TL;DR
When you’re migrating many services through the same steps, parallelize by step, not by service. Sweep one type of change across all services, then the next – it compounds learning, catches inconsistencies early, and makes automation viable. But recognize which services don’t fit the pattern: architecturally unique services should still be migrated serially.
The Problem
You’ve probably seen the shape of this problem before. You’re planning next quarter’s migration – could be Kubernetes, a new database engine, a cloud provider switch, a major framework version bump. You count the services. You count the engineers. The math doesn’t work.
Here’s what it looked like for us: 2025 Q4 planning, 21 services still running on ECS (Amazon’s container orchestration service) that needed to move to EKS (their managed Kubernetes platform). A headcount cut left us with 4 engineers. Each service migration had been taking 3-4 weeks of effort. The project had already been running since January 2024 – nearly two years – and the serial execution model from the previous quarter had required 8 engineers for 19 services. We had half the people, more services, and a timeline that was starting to feel permanent.
Nobody was telling us it had to be done next quarter. Our management said, “It’s okay if we can’t, don’t worry.”
But you know what happens to migrations that stretch for many months. They lose momentum. Engineers rotate off. Institutional knowledge erodes. The remaining services – always the hardest ones – sit in a permanent “next quarter” backlog.
Why serial breaks down
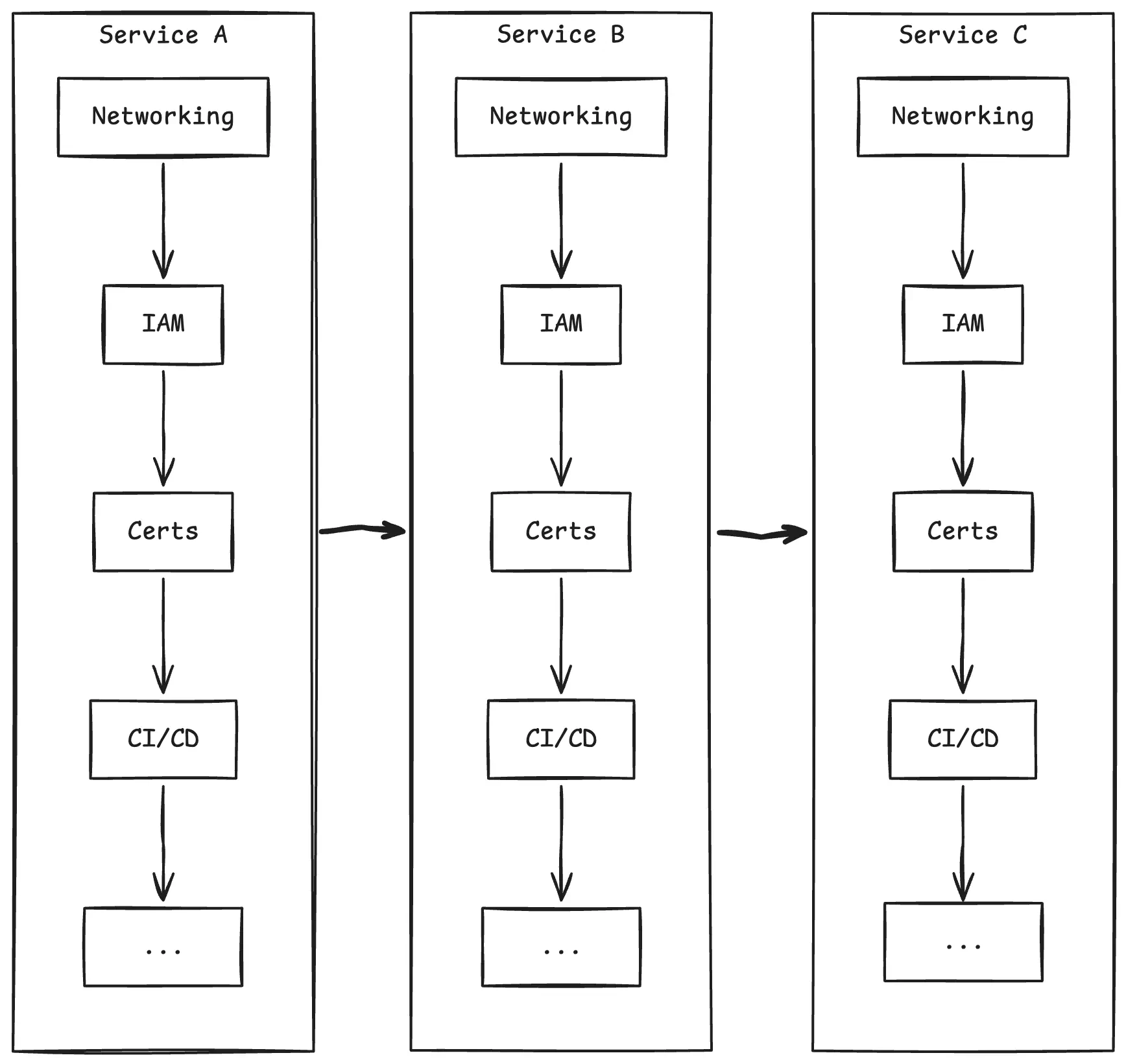
The default migration approach is serial: one engineer owns a service end-to-end and walks it through every step – networking, permissions, environment adjustments, certificates, CI/CD, DNS, cleanup. This works fine for a couple of services. This breaks down at scale.
The engineer context-switches across completely different types of work – networking, then application configuration, then debugging a permissions issue – and never builds deep fluency in any of them. Services are unique snowflakes – each with its own code style, dependency patterns, and configuration quirks. Serial migration means absorbing that uniqueness for every service, at every step.
Even worse – learning stays siloed. An engineer who figured out a networking edge case in week 2 can’t help the engineer who hits the same issue in week 6 – by then, they’ve moved on. Everyone is deep in a different service, at a different stage. The team can’t effectively pair, review, or unblock each other.
The Insight
When I looked at what we’d actually done in Q3 – service by service, step by step – the pattern was obvious in hindsight: we were doing the same work over and over again. Networking, permissions, application setup – identical across services.
It only looked unique because we were thinking one service at a time.
Serial Migration Strategy
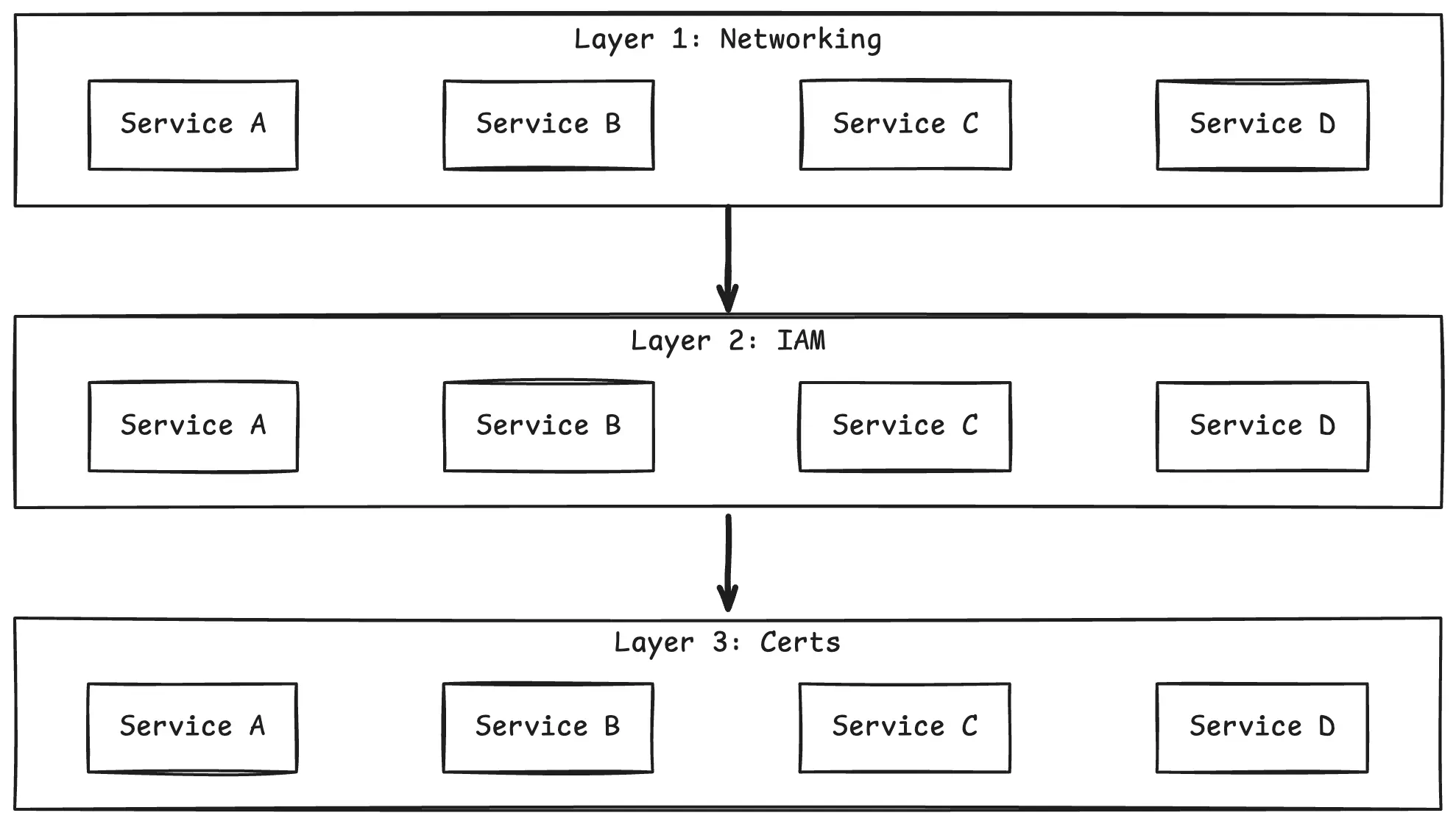
What if we flipped the axis? Instead of completing all steps for one service before moving to the next, complete one step across all services before moving to the next step.
That’s the core of the layer-based approach. A layer is one type of infrastructure or configuration change, applied to every service in the migration scope. You sweep through all services at one layer, validate, then move to the next layer.
Layer-based Migration Strategy
Why this works
- Repetition builds expertise. By the third service in a layer, you’ve seen the pattern. By the tenth, you’re fast.
- Cross-service checks catch errors early. When you’re applying the same change to 20 services in a row, inconsistencies become obvious.
- Learning compounds across the team. Everyone works the same layer simultaneously – discoveries spread instantly instead of weeks later.
- Automation becomes viable. Identical changes across services are exactly what tooling excels at – predictable patterns with minor per-service variations.
Defining Your Layers
The number of layers depends on your migration. Ours had 14. Yours might have 8 or 20.
Here are the categories we found useful, grouped by concern:
- Discovery: mapping downstream dependencies – services, databases, endpoints, protocols
- Connectivity: networking between environments, firewall configurations
- Identity: permissions, service accounts, trust policies, OIDC configuration
- App level security: certificates, TLS termination, WAF rules
- Application: runtime configuration, environment variables, secrets, logging adjustments
- Delivery: CI/CD pipelines, ingress and routing, traffic management for gradual rollout
Your categories will differ. The names don’t matter – the decomposition does.
How to decompose your own migration
Start from a single service migration you’ve already done. List every change you made, in order. Group changes by type, not by when they happened. Each group is a candidate layer.
Then validate: can this layer be applied independently of the next one? Can you validate it before moving on? If yes, it’s a good layer boundary. If two changes are tightly coupled and can’t be validated separately, merge them into one layer.
One rule we learned the hard way: one layer per pull request. Early on, some PRs combined changes from multiple layers – networking and permissions in the same commit. Validation got complex, rollbacks got messy. Keep them separate.
Execution Model
A layer sweep works like this: the team takes on a layer, splits the service list among themselves, and each engineer applies that layer to their assigned services. Everyone works the same type of change simultaneously.
One engineer can realistically sweep a single layer across 6-8 services in a day. That number surprises people – until they know the tooling. We paired the layered methodology with AI-assisted automation that handled the repetitive configuration work across services. But the important thing is: the layer-based structure is what makes that automation possible.
When every service needs the same type of change with minor variations, you can build prompts, scripts, and validation checks that apply across the board. Serial, per-service work is too varied to automate effectively. The AI tooling story – what worked, what failed, and where human judgment was irreplaceable – is the subject of the next post in this series.
During execution, the team meets briefly to sync on edge cases – because the work is homogeneous, an edge case in one service is immediately relevant to every other service going through the same layer.
Progress tracking
A simple table – one column per layer, one row per service – serves as the source of truth. The team updates it in real time. Status per cell: not started, in progress, done, blocked, not applicable. This sounds basic, but it’s surprisingly effective. You can see at a glance where the project stands, which layers are complete, and where blockers are clustering.
Services that don’t fit
Not every service fits the pattern. In our case, 4 out of 21 services were architecturally complex enough that the layered approach didn’t help – they required deep, per-service analysis that negated the speed advantage.
We recognized this early and migrated them serially, with dedicated engineers working in parallel with the layer sweeps. Trying to force these into the pattern would have slowed everything down.
The lesson: the layer-based approach is a force multiplier for homogeneous work. When a service is genuinely unique, serial migration is the right tool. Budget for both.
Coordination That Matches the Work
The coordination model that works during one phase can hurt you in the next.
During layers: synchronize
When the whole team works the same layer, synchronous coordination is natural and cheap. Team syncs are short because everyone has context on the same type of work. An edge case discovered by one engineer is immediately useful to the others. Knowledge transfer happens without any deliberate mechanism – the work itself is identical.
During traffic switching: structure async handoffs
When the project moves from layer execution to per-service traffic switching, the work diverges. Each service has its own timeline, its own blockers, its own owning team with a different schedule. Synchronous coordination becomes expensive – the team is now working on different problems.
This is where a handoff log pays for itself. A shared document – not “made progress on Service X” but the actual PR link, the specific blocker, the decision to skip WAF configuration for this service, and why. What made it work: specificity over summary, explicit ownership, and early surfacing of blockers.
We heavily used this approach during the last phase of migration – the traffic switch – when two team members went to our SF hub to be on site with service owners, and two stayed in Berlin. But this isn’t a timezone trick – it works for co-located teams just as well. Fewer meetings, more focused execution, and a written record that prevents “I thought you were handling that” conversations.
The lesson: match the coordination model to the shape of the work. When work is homogeneous, synchronize. When it diverges, structure async handoffs and get out of each other’s way.
The Traffic Switch Cadence
Layer execution is predictable. Traffic switching is where the surprises live.
We used a graduated weekly cadence: Monday preflight (verify hostnames, certificates, ingress, autoscaling, dashboards – deploy one instance), Tuesday scale up and shift 1% of traffic, Wednesday observe and fix, Thursday shift to 50%, Friday observe and fix, following Monday shift to 100%.
The observation days weren’t idle – they were when most debug work happens. Issues that don’t surface at 1% show up at 50%. Fixes discovered for one service often apply to others in the same batch.
Batch your traffic switches. Running multiple services through this cadence simultaneously amortizes the coordination overhead – the preflight checklist, once built, applies to every service.
When This Works (and When It Doesn’t)
The layered approach is not universal. It works well under specific conditions.
Use layers when:
- The migration is decomposable into independent, repeatable steps
- The same type of change applies across many targets with minor per-service variations
- Changes can be batch-validated – all services at one layer before moving on
- The team is small relative to the workload and needs a force multiplier
Use serial when:
- Services are architecturally unique and complex, and require deep, per-service analysis
- The number of targets is small enough that coordination overhead outweighs the parallelization benefit
This is not an either/or decision. In our migration, the layered approach covered 17 of 21 services. The remaining 4 were migrated serially. Recognizing which services don’t fit the pattern early is just as important as the pattern itself.
What We’d Do Differently
Start the handoff log from day one. We introduced it when the team split across workstreams during traffic switching. In retrospect, the discipline of specificity and explicit ownership helps even when everyone is in the same room working the same layer.
Run validation sweeps after each layer, not at the end. We deferred some validation to later phases, when we did traffic switch on preproduction environments, which made fixing errors more expensive and created pressure during the most time-sensitive window.
Define service owner readiness criteria upfront. Some services reached the traffic switch phase with owners who weren’t fully briefed, dashboards that weren’t adjusted, etc. Clear criteria before the switch phase would have eliminated friction during the highest-pressure window.
Plan for the energy arc. An intensive, multi-month migration grinds people down. Build rotation points into the plan. Bring fresh perspective at deliberate moments – especially before the production switch phase.
Track decisions explicitly, separate from action items. Some decisions logged in the handoff document were missed because they were buried among task updates. A dedicated “decisions” section prevents teams from diverging without realizing it.
Key Takeaways
- Flip the axis. When many services go through the same steps, parallelize by step, not by service. The efficiency gain comes from repetition, shared learning, and automation – not from working harder.
- Define your layers by decomposing a single service migration. Group changes by type, validate that layers can be applied independently, and enforce one layer per merge request.
- Match coordination to the shape of the work. Synchronize when work is homogeneous. Structure async handoffs when it diverges.
- Recognize what doesn’t fit the pattern. Some services are genuinely unique. Budget for serial migration alongside the layer sweeps.
- The traffic switch is its own phase. Layer execution is predictable. Traffic switching is where surprises live. Treat it with a graduated cadence and observation days.
- The methodology enables the tooling, not the other way around. We paired layer-based execution with AI-assisted automation – and that’s what made one engineer sweeping 6-8 services in a day realistic. But the automation only worked because the layers created predictable, repeatable patterns. That story is next.
If this feels like a problem you’ve hit – or you’re about to – I’d like to hear your approach. Same constraint, different solution? A migration where layers didn’t work? Drop a comment.