
Legacy architectural decisions often carry hidden costs. Here’s how questioning a storage configuration saved us a hundred thousand and taught some lessons about S3.
This is a technical walkthrough of identifying, analyzing, and solving two specific S3 cost optimization problems I faced recently: eliminating unnecessary data and implementing intelligent storage tiering.
Note: All mentioned AWS prices are from January 2025 in the us-east-1 region. AWS pricing and features may have changed since the publication.
What was the cause
Picture this: In December 2024, two S3 buckets quietly consumed about $19,500. The price is just for one month. That’s nearly $235,000 annually, but the size of buckets slowly grows, so it’s going to be more. These buckets are for JFrog Artifactory, which supports AWS S3 as a file storage. The first bucket contains CI/CD builds and cached third-party artifacts — essential data we need daily. The second bucket is the replica in another region. This build data is important, yet paying $120,000 a year to duplicate that data seems overkill.
Now the question is: WHY do we have such a setup with replication? As always happens, that was configured long ago, so no one knows by now.
Let’s give this a fresh look: S3 provides 11-nines durability by design; if something gets deleted by accident, we can always re-run CI/CD and build that again. Does replication provide any value?
The problem statement is simple: the buckets are enormous, we pay half the price for nothing, and the amount of data might grow more.
- Two S3 buckets: main in us-east-1 and replica in us-west-2
- About 340TB each
- 21+ million objects per bucket
- Average object size: 17MB
- 7% monthly growth rate based on the last 12 months’ trend
The two-fold solution to that was not that trivial, though.
Addressing the unpredicted S3 bucket growth and access patterns
By the design of S3 service, a client (you or your application) should specify the storage class when uploading the object to an S3 bucket; there is no thing like “default storage class for new objects”.
Surprisingly, despite a versatile configuration options for S3, JFrog Artifactory does not allow setting storage classes for the objects it stores. So, everything you store is sent to S3 with the Standard storage class.
On a large scale, with many teams and projects, it is pretty hard to predict the lifetime and the frequency of one or other artifact for the particular team. Auto-cleanup options are built into Artifactory, but they do not answer the retention questions anyway: How long? How frequent?
Luckily, AWS has two powerful things to address these issues:
Benefits of Intelligent-Tiering Storage class
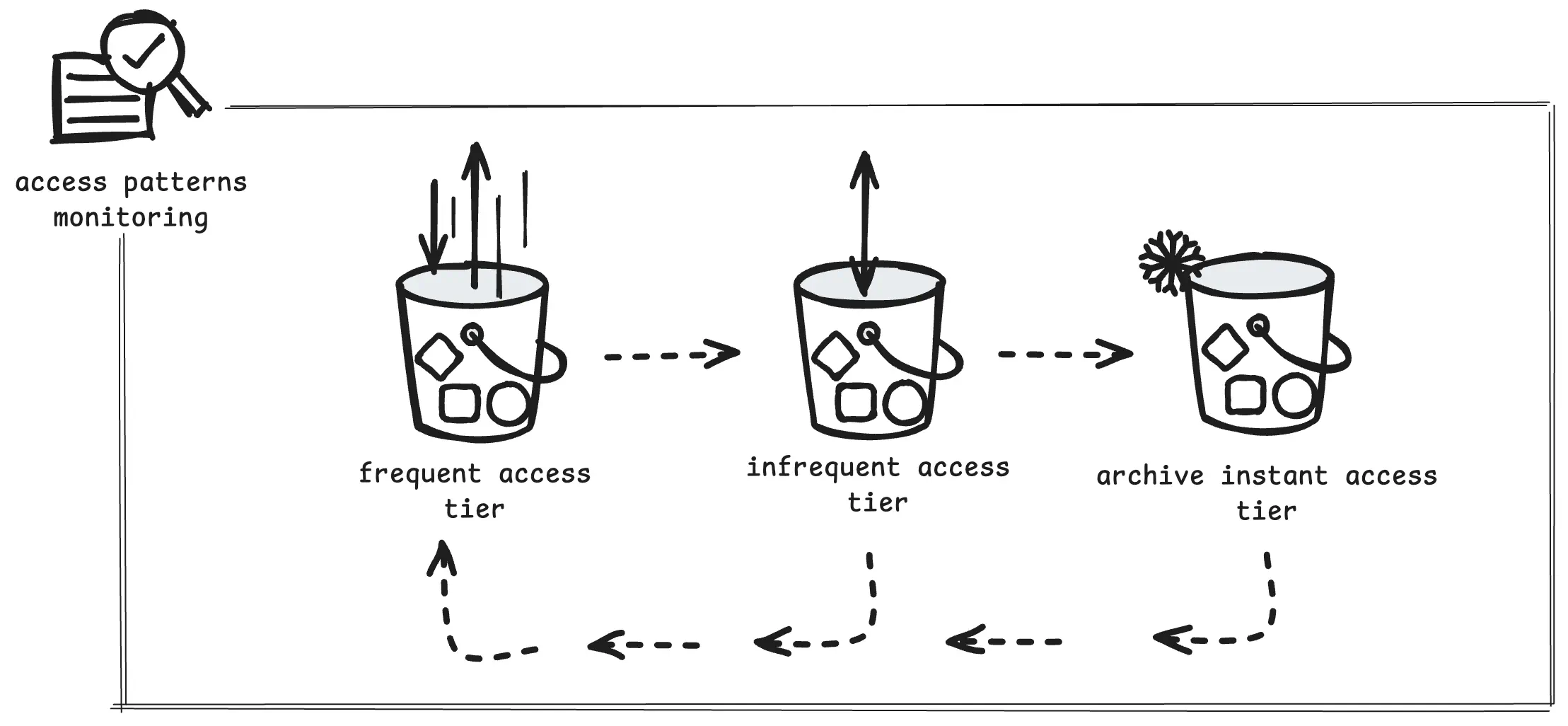
As its name implies, Intelligent-Tiering automatically defines the best access tier when access patterns change. There are three basic tiers: one is optimized for frequent access, another for infrequent access, and a very low-cost tier, which is optimized for rarely accessed data.
For a relatively small price, which is negligible on scale, S3 does the monitoring and tier transition of the objects:
- Monitoring: $0.0025 per 1,000 objects/month
- Storage for GB/month:
- $0.021 — frequent tier: object stored here by default
- $0.0125 — infrequent tier: object moved here after 30 days without access
- $0.004 — archive tier: object moved here after 90 days without access
The vast advantage of Intelligent-Tiering comes with the infrequent and archive tier prices on scale.
But note that objects smaller than 128 KB are not eligible for auto tiering.
S3 Intelligent-Tiering
Lifecycle Configuration to move S3 objects between storage classes
So now the question is: how to move all the objects to Intelligent-Tiering, old and any new ones?
Here comes Lifecycle Configuration. S3 Lifecycle also manipulates objects, but the key difference between Intelligent-Tiering and Lifecycle Configuration is that Configuration does not have the access pattern analysis as a trigger — the only trigger for Configuration is the time (e.g., trigger in N days).
However, a trigger by time mark is precisely what’s needed when your software does not support the custom storage classes — you want to move objects as soon as possible to Intelligent-Tiering using Lifecycle Configuration.
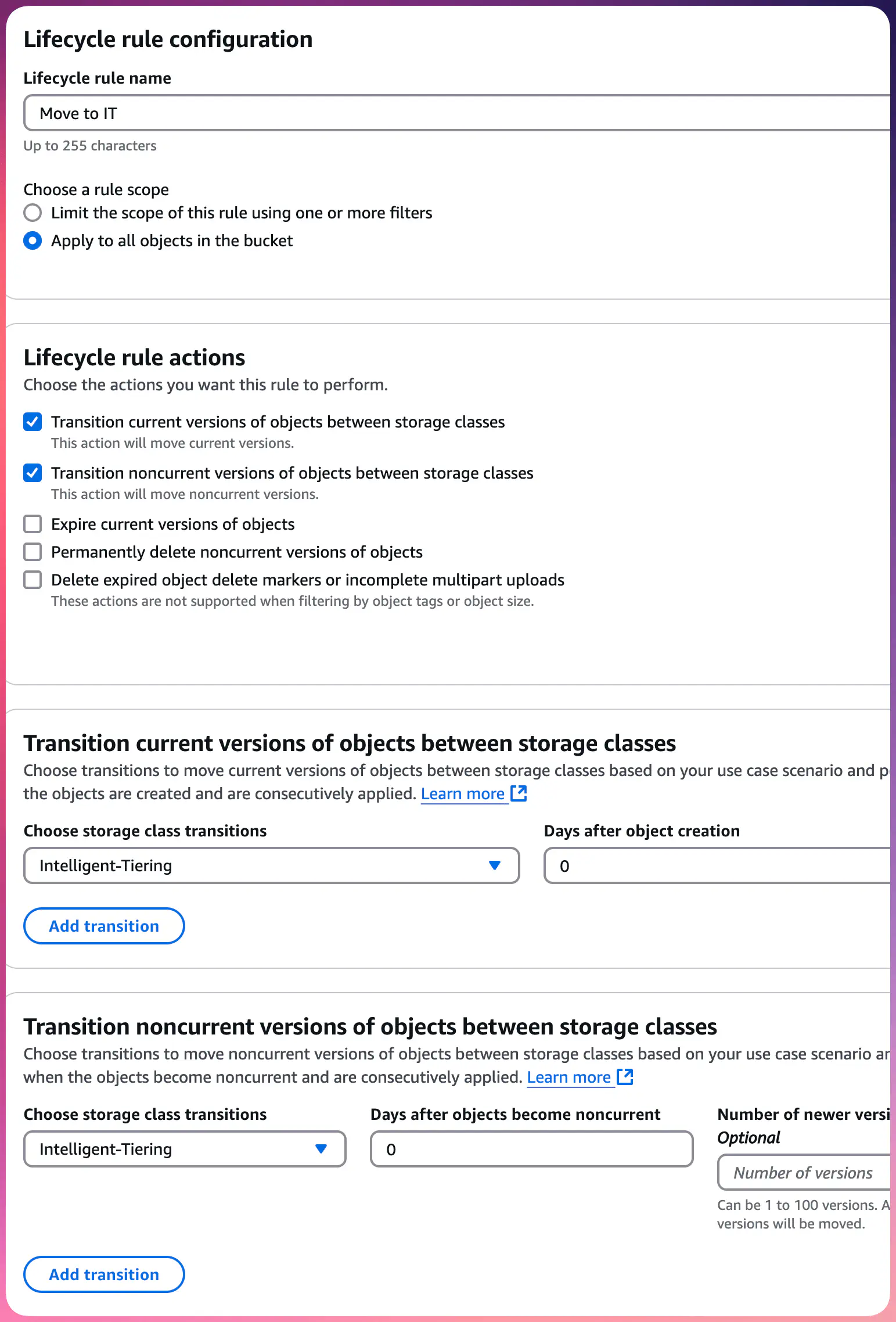
Here’s how you need to configure the Lifecycle to move all the objects to Intelligent-Tiering:
- Apply to all objects in the bucket
- Actions:
- The 1st option — Transition current versions of objects between storage classes
- The 2nd option — Transition noncurrent versions of objects between storage classes
- Specify Intelligent-Tiering for “Transition current version” and “Transition noncurrent versions”
- Set 0 as the number of “Days after object creation” and “Days after objects become noncurrent”
S3 Lifecycle Rule: Move to Intelligent-Tiering
A zero value here does not mean an immediate change of the storage class: by design, the transition will be executed at midnight UTC from the object upload date. For existing objects, the transition will begin at midnight UTC after the lifecycle rule is applied.
Lifecycle Configuration has a price of $0.01 per 1,000 Transition requests, which technically adds $0.00001 as the one-time cost of each object affected by the policy.
For example, in my case, moving 21 million objects to the Intelligent-Tiering class had a one-time cost of $210, but ROI for this is much more significant the next month.
The effect of applying Intelligent-Tiering comes in time. At least 60 days should pass to see the real difference: 30 days to trigger the first tiering relocation and then another 30 for the next month’s usage so you can compare.
Based on Storage Lense and Storage Class Analysis statistics, I expect about 60% of the objects to remain in the archive tier, reducing the total costs of the primary S3 bucket by 48%.
Untrivial termination of a large S3 bucket
How hard can it be to empty and delete the bucket with 21 million objects inside? (To clarify: S3 does not allow deletion of a non-empty bucket)
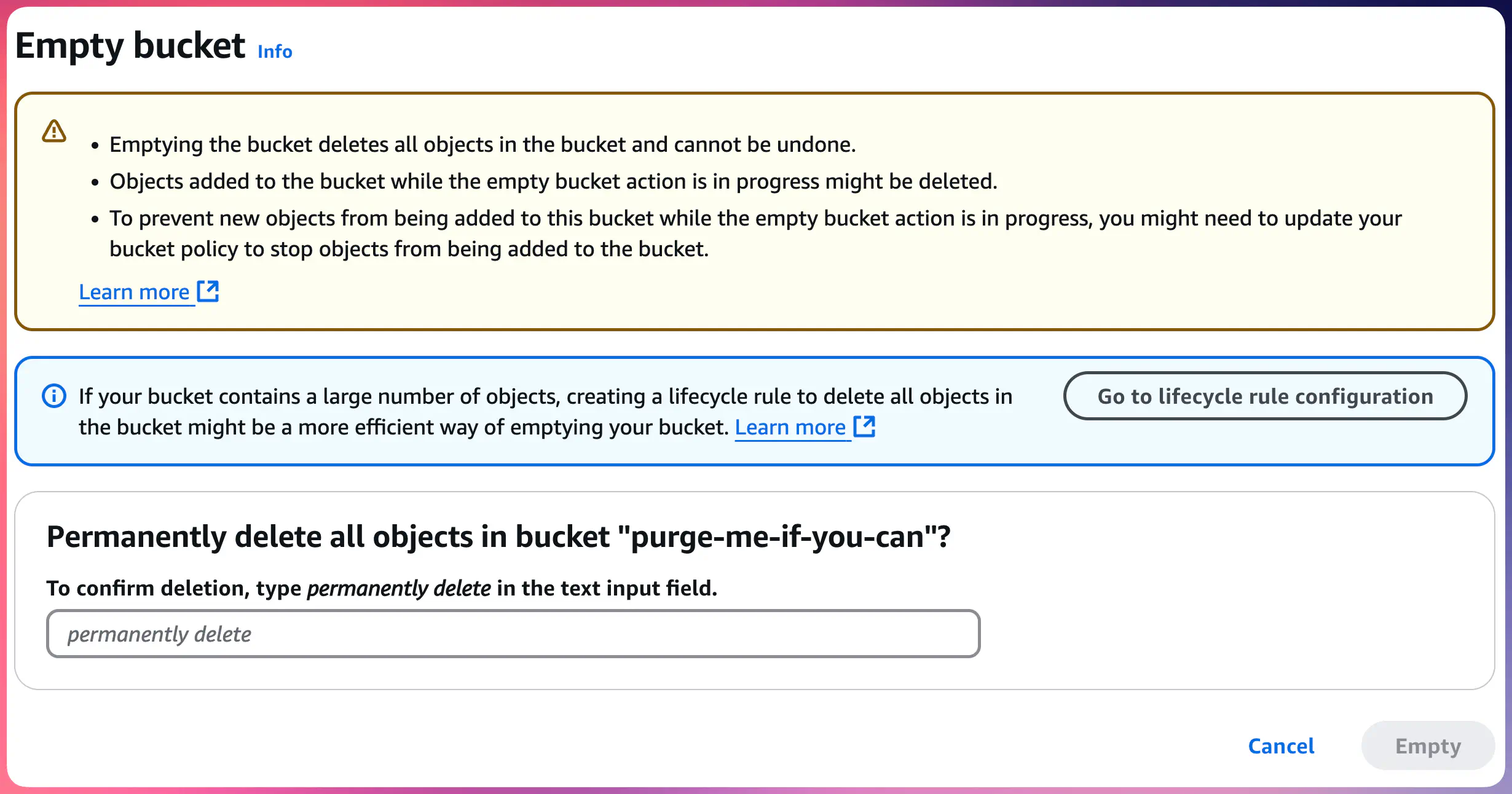
The most obvious way, at first glance, would be to use the AWS S3 web Console option called “Empty”, right?
S3 Empty Bucket
Alas, it is not that simple.
When you go that way, it is your browser who removes the objects by sending API calls to AWS. There is no background job for you. It does that efficiently, sending DELETE requests in 1000-item batches, but it does that as long as your IAM session remains active (or the browser window remains open, whatever ends first).
If your bucket has Bucket Versioning enabled, “Empty” action will not remove all the object versions.
So then we have two other options:
- Either run some script that removes all object versions (including current, older, and null versions) and delete markers.
- Or set up a couple of Lifecycle Configuration rules to purge a bucket in an unattended way.
If the total number of objects is relatively small, e.g., up to few hundred thousand, it is feasible to run a script that removes all object versions and delete markers.
Click here to see the code snippet
#!/usr/bin/env python3
import sys
import boto3
def purge_bucket_interactive(bucket_name: str) -> None:
"""
Display the bucket ARN and region, warn the user, and prompt them to type
'YES' in uppercase. If confirmed, permanently remove all object versions
(including current, older, and null versions) and delete markers.
"""
# We use the S3 client to query bucket location info
s3_client = boto3.client("s3")
response = s3_client.get_bucket_location(Bucket=bucket_name)
region = response.get("LocationConstraint") or "us-east-1"
# Construct the bucket's ARN (for standard S3 buckets, the region is not typically embedded)
bucket_arn = f"arn:aws:s3:::{bucket_name}"
print(f"Bucket ARN : {bucket_arn}")
print(f"Bucket region: {region}")
print("WARNING: This will permanently remove ALL VERSIONS of every object.")
print("It is NOT REVERSIBLE!!!\n")
confirm = input("Type 'YES' in uppercase to proceed with the permanent removal: ").strip()
if confirm != "YES":
print("Aborted. No changes made.")
return
# Proceed with deletion
print("Starting purge... This might take a while.")
# Use the S3 resource to delete all versions
s3 = boto3.resource("s3")
bucket = s3.Bucket(bucket_name)
bucket.object_versions.all().delete()
print("All object versions and delete markers have been removed.")
if __name__ == "__main__":
if len(sys.argv) < 2:
print(f"Usage: {sys.argv[0]} <bucket_name>")
sys.exit(1)
bucket_to_purge = sys.argv[1]
purge_bucket_interactive(bucket_to_purge)
First, you need to pause the versioning. Then, create two Lifecycle Configuration rules.
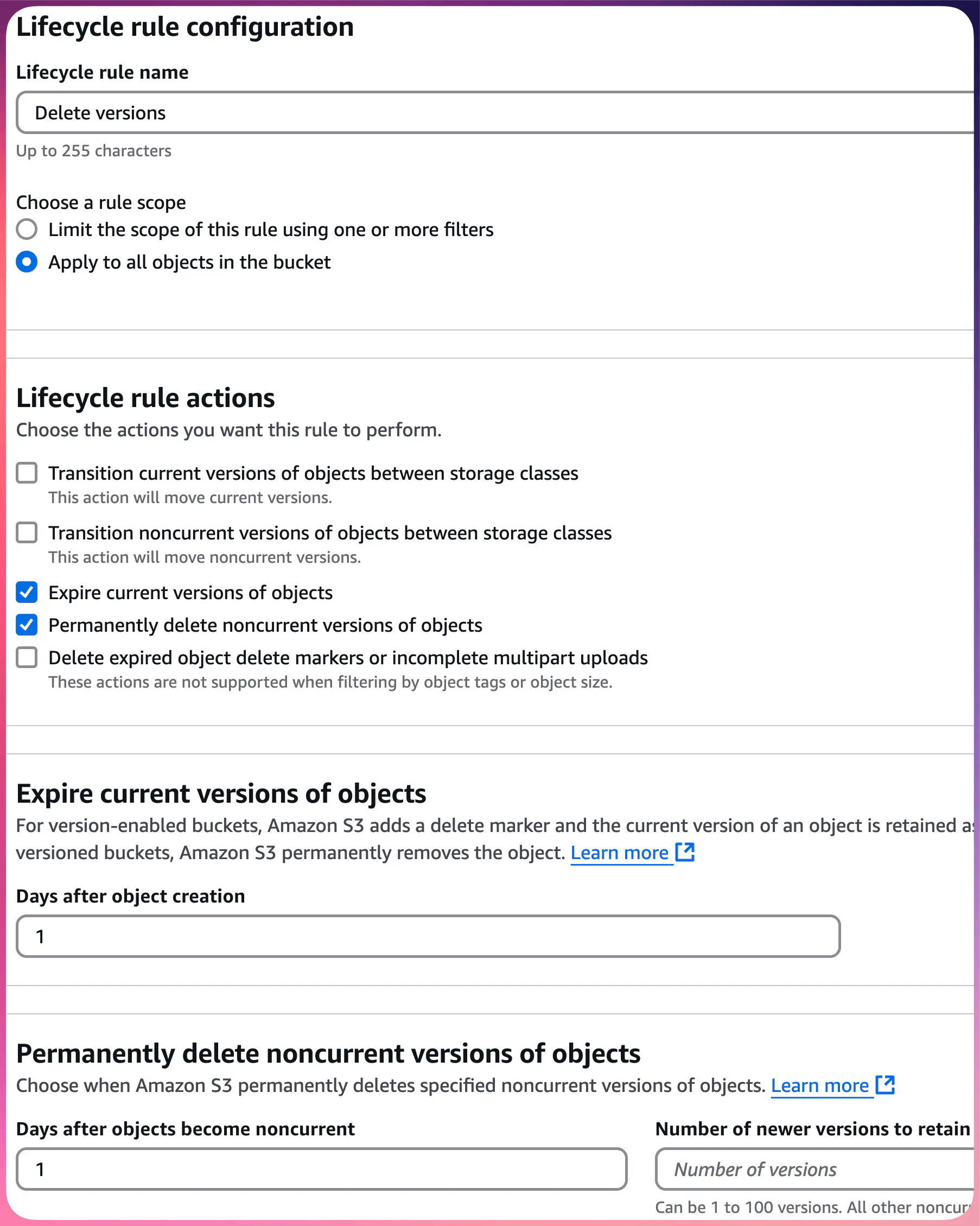
The first rule will delete all versions of the objects:
- Apply to all objects in the bucket
- Actions:
- The 3rd option — “Expire current versions of objects”
- The 4th option — “Permanently delete previous versions of objects”
- The number of days you would like the current version to expire, to do as soon as possible, enter 1 in the text box. That makes it “1 day”.
- For the days after which the noncurrent versions will be permanently deleted, enter 1 in the text box. That makes it “1 day” of being noncurrent.
S3 Lifecycle Rule: Delete Versions
Due to how S3 versioning works, a special DELETE marker will be created for each object processed by the first rule. To handle the delete markers, you must create a new lifecycle rule, as you won’t be able to select the option to delete the “delete markers” in the first rule.
For the second lifecycle rule, the steps are similar, and the only difference is that you must select the 5th and last option: “Delete expired object delete markers or incomplete multipart uploads.” Select both the options — “Delete expired object delete markers” and “Delete incomplete multipart uploads” — and set it to 1 day.
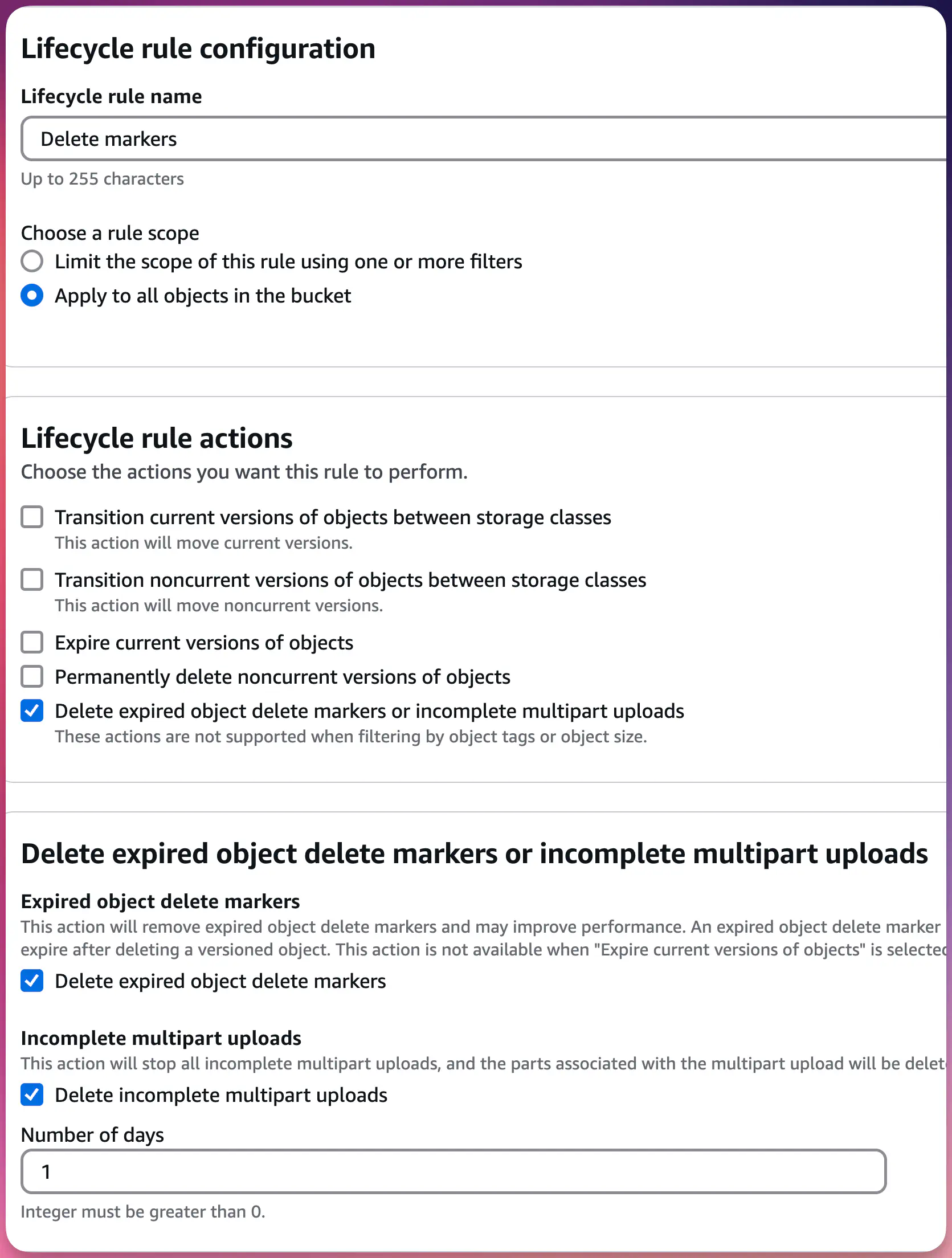
S3 Lifecycle Rule: Delete Markers
Implementation Results
- Immediate cost reduction: $120,000 baseline or $270,000 if the 7% growth rate remains
- Projected additional cost reduction from Intelligent-Tiering: 48% — means the drop of the baseline price of the main bucket from $120,000 to roughly $63,000 a year
- One-time transition cost: $210
- Implementation time: 2 days
- Storage class transition completed in 1 day
The final $63,000 versus $235,000 is a nice result. Combining the data from Intelligent-Tiering with built-in Artifactory retention policies can reduce that even more. However, it would require some custom logic wrapped around.
Key Takeaways
- Challenge your architecture decisions overtime.
- Challenge redundancy — is it providing real value?
- Regular cost reviews can be a source of quick wins.
- Let automated solutions do the job, and do not overengineer things.
- AWS Simple Storage Service, despite its name, might be tricky, but AWS has a bunch of tools to help you.
S3 Lifecycle rules proved their worth twice: first by automating our transition to Intelligent-Tiering despite Artifactory’s limitations and then by cleaning up millions of versioned objects without operational overhead.