
With a solid foundation in AWS API Gateway and Lambda for serverless architecture, my recent deep dive into these cloud computing services felt like uncovering new layers in familiar territory. This article aims to be a comprehensive guide for developers and DevOps professionals looking to master serverless solutions using AWS and Terraform.
The article provides an in-depth guide to combining AWS API Gateway V2 HTTP API (yes, this is the official name of that service 😄) and AWS Lambda services to implement a simple, robust, and cost-effective serverless back-end using Terraform.
The journey was enlightening and engaging, especially as I were transforming these services into Infrastructure as Code. Through this article, I aim to share those moments of insight and the practical, hands-on tips that emerged from weaving these AWS services into a seamless, serverless architecture.
Navigating the System Design: HTTP API Gateway and Lambda in Action
Beginning our journey, we examine the complexities of serverless architecture, focusing on HTTP API and Lambda. A comprehensive system diagram will guide us as we analyze each component’s function and their collaborative roles in the larger infrastructure.
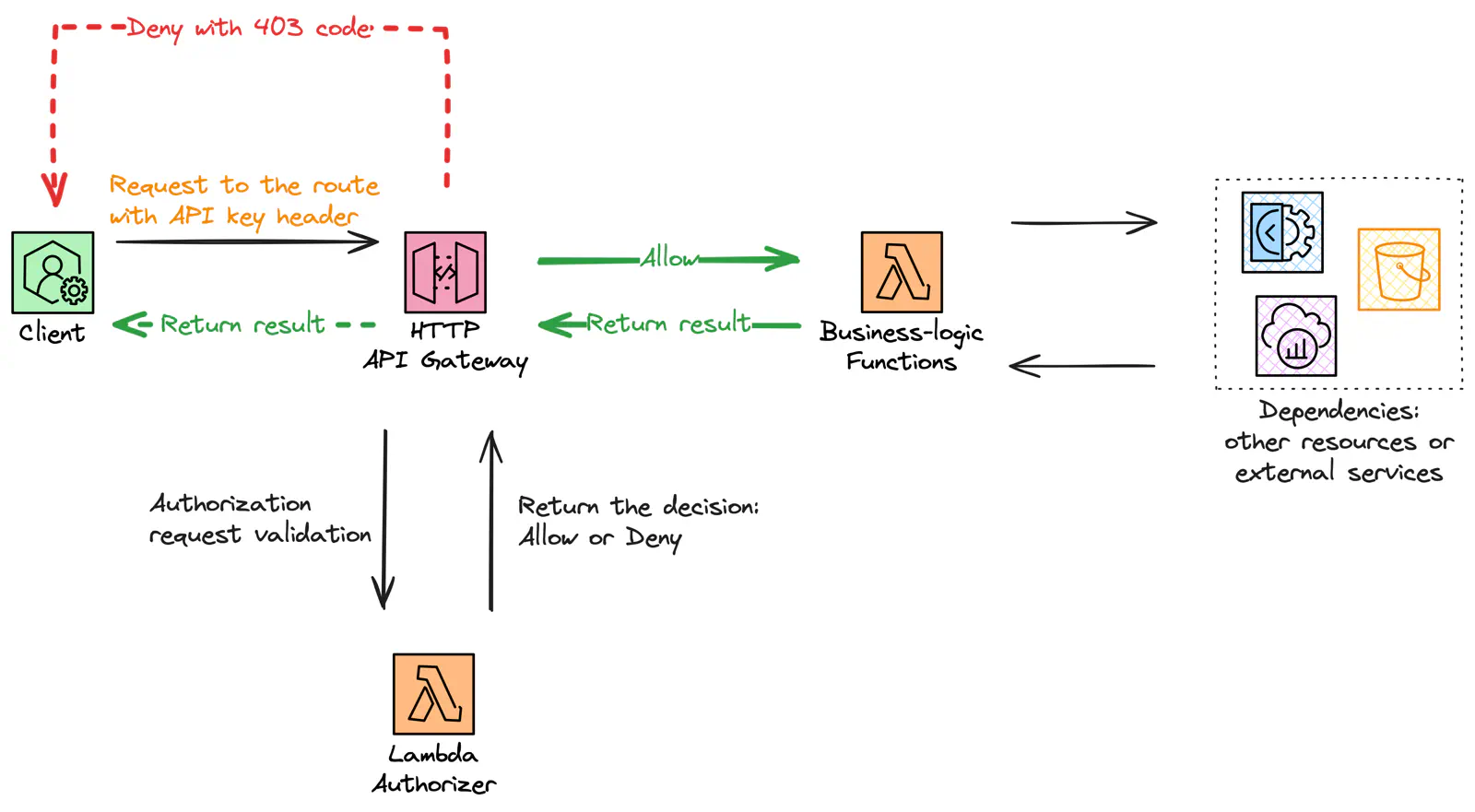
HTTP API Gateway and AWS Lambda flowchart
In our architecture, the HTTP API delegates access control to the Lambda function called “Authorizer”. This function stands as the gatekeeper, ensuring that only legitimate requests pass through to the underlying business logic.
The HTTP API can have multiple routes (e.g., “/calendar,” “/meters,” and so on) and use different Authorizers per route or a single one for all of them. Clients that send their requests to the API must include specific identification information in their request header or query string. In this project, I go with a single authorizer to keep it simple.
Upon receiving a request, the API service forwards a payload to the Authorizer containing metadata about the request, such as headers and query string components. The Authorizer processes this metadata (headers, in my case) to determine the request’s legitimacy.
The decision, Allow or Deny, is passed back to the API, and if allowed, the API service then forwards the original request to the back-end, which, in this case, is implemented by additional Lambda functions. Otherwise, the client gets a response with a 403 status code, and the original request is not passed to the back-end.
Behind The Decision: Why Such a Setup?
Choosing the right architectural setup is critical in balancing simplicity, cost-efficiency, and security. In this section, we uncover why integrating AWS HTTP API Gateway with Lambda Authorizer is a compelling choice, offering a streamlined approach without compromising security.
provided.al2 reaches end of life on June 30, 2026 — this guide already uses provided.al2023, which is supported until June 30, 2029.Cost-Effectiveness: Balancing Performance and Price
The AWS HTTP API is noteworthy for its streamlined and simple design compared to other API Gateway options. That translates directly into cost savings for businesses. Its efficiency makes it an ideal choice for cost-effective serverless computing, especially for those looking to optimize their cloud infrastructure with Terraform automation. Here is a more detailed comparison of different API Gateway options — Cost optimization.
Security with Lambda Authorizer. This option means a Lambda function used for authorization, which is lean and efficient. It generally requires a bare minimum of resources. It executes quickly, particularly when configured with the ARM-based environment and 128M RAM allocation, costing $0,0000017 per second of running time, with $0.20 per 1M requests per month.
💰 This pricing and performance combination are well-suited for rapid, lightweight authorizations. Together with AWS Lambda as a back-end, it makes a cost-effective solution. For example, if we add a few more Lambdas to back-end and assume that our setup receives 10000 requests per month, it would cost around $0.6 per month. Here is the link to detailed calculations — AWS Pricing Calculator.
Simplicity in Configuration: The Power of Header-Based Authorization
A header-based authentication method facilitates straightforward client-server communication, often requiring less coding and resources to implement compared to more complex schemes.
Although HTTP API offers stronger JWT-based authorization and mutual TLS authentication, header-based authorization remains a suitable choice for simpler applications that prioritize ease and quickness. By the way, there is also an option for IAM-based authorization whose core idea is the “private API” or internal usage of the API (e.g., solely inside the VPC, no internet), but with “IAM Anywhere,” this can be expanded to practically anywhere. 😁
This architecture suits applications requiring rapid development and deployment without complex authorization mechanisms. It’s ideal for small to medium-sized serverless applications or specific use cases in larger systems where quick, cost-effective, and secure access to APIs is a priority.
💡 Imagine a retail company wanting to manage its inventory efficiently. By leveraging AWS API Gateway and Lambda, they can develop a system where each item’s RFID tags are scanned and processed through an API endpoint. When a product is moved or sold, its status is updated in real-time in the database, facilitated by Lambda functions. This serverless architecture ensures high availability and scalability and significantly reduces operational costs, a crucial factor for the highly competitive retail industry. This example showcases how our serverless setup can be effectively utilized in retail for streamlined inventory tracking and management.
Exploring AWS Lambda: Features and Integration
Diving into AWS Lambda, this section explores its features and indispensable role within the serverless infrastructure. We will unravel the complexities of Lambda functions and examine the practicalities of deploying and managing these functions within the project.
AWS Lambda Runtime and Deployment Model
🚀 Choosing the AWS Lambda runtime arm64, combined with the OS-only runtime based on Amazon Linux 2023, strategically boosts cost efficiency and performance. This choice aligns with the best practices for serverless computing in AWS, offering an optimal solution for those seeking to leverage AWS services for scalable cloud solutions.
Particularly effective for Go-based functions, this runtime configuration is lean yet powerful. For applications in other languages, delving into language-specific runtimes based on AL 2023 can also leverage the latest efficiencies of AWS-managed operating systems.
The .zip deployment model is chosen for its simplicity, avoiding additional management of the image registry (ECR) and Docker images. Also, AWS automatically patches .zip functions for the latest runtime security and bug fixes.
Efficient Terraform Coding for AWS Lambda
In our architecture, AWS Lambda functions serve dual purposes — as an authentication gatekeeper and a robust back-end for business logic. Despite varying code across functions, their configurations share much of similarities.
By adhering to the DRY (Don’t Repeat Yourself) principle, I have crafted a Terraform module to streamline the management of Lambda functions and their dependencies. This approach ensures maintainable and scalable infrastructure. The module’s structure is as follows:
aws_lambda_function— to describe the core configuration of the functionaws_iam_role+aws_iam_role_policy+aws_iam_policy_document— to manage the access from Lambda to other resources (e.g., SSM Parameter Store)aws_cloudwatch_log_group— to keep the execution logsaws_ssm_parameter— to store sensitive information (e.g., secrets) and other configurations that we should keep separate from the source code.
This Terraform module implements a project-specific use case for Lambda functions. However, if you’re seeking for a generic all-in-one module for AWS Lambda, I recommend checking out this one — Terraform AWS Lambda Module by Anton Babenko.
To efficiently develop Terraform code for Lambda functions, use the following techniques:
- Use local values, expressions, and variables to implement consistent naming across different resources logically grouped by a module or project;
- Use function environment variables to connect the code with SSM Parameter Store parameters or Secrets Manager secrets to protect sensitive data like tokens or credentials;
- Use
for_eachmeta-argument andforexpression to reduce the amount of code and automate the configuration for resources of the same type (e.g.,ssm_parameter) or code blocks within a resource.
Below is a practical example illustrating these Terraform strategies in action:
locals {
full_function_name = "${var.project_name}-${var.function_name}"
}
resource "aws_lambda_function" "this" {
function_name = local.full_function_name
role = aws_iam_role.this.arn
architectures = ["arm64"]
filename = var.deployment_file
package_type = "Zip"
runtime = "provided.al2023"
handler = "bootstrap.handler"
timeout = var.function_timeout
environment {
variables = { for item in var.function_ssm_parameter_names : upper(replace(item, "-", "_")) => aws_ssm_parameter.function_ssm_parameters[item].name }
}
}
resource "aws_ssm_parameter" "function_ssm_parameters" {
for_each = var.function_ssm_parameter_names
name = "/projects/${var.project_name}/lambda/${var.function_name}/${each.value}"
type = "SecureString"
key_id = data.aws_kms_alias.ssm.arn
value = "1"
lifecycle {
ignore_changes = [
value,
]
}
}
resource "aws_cloudwatch_log_group" "this" {
name = "/aws/lambda/${local.full_function_name}"
log_group_class = "STANDARD"
retention_in_days = 7
}
The complete terraform module code is available in the project repository.
In this Terraform code, I deliberately hardcoded specific arguments for an optimal Lambda runtime configuration, ensuring efficiency and performance.
Then variables and local values, set only once, implement a naming convention for all resource arguments, making it easy to understand the infrastructure and change the naming and attributes later.
for_each and for. I used the for_each meta-argument to dynamically create SSM Parameter resources and the for expression to configure environment variables in AWS Lambda. This also means that if the function_ssm_parameter_names variable value is not provided, then Terraform does not create either SSM parameter resources or the environment code block inside the Lambda resource because the default value of that variable is an empty set.By the way, I have another blog post that explains several techniques to enhance your Terraform proficiency — check it out!
Invoking Lambda: Permissions and Resource-Based Policies
Configured with just a few input variables, the Terraform module efficiently outputs the aws_lambda_function resource. This streamlined output is then adeptly used to facilitate subsequent configurations within the HTTP API.
module "lambda_api_gw_authorizer" {
source = "./modules/lambda"
deployment_file = "../backend/lambda-apigw-authorizer/deployment.zip"
function_name = "api-gateway-authorizer"
project_name = local.project_name
function_ssm_parameters = [
"authorization-token"
]
}
module "lambda_calendar_backend" {
source = "./modules/lambda"
deployment_file = "../backend/lambda-calendar-backend/deployment.zip"
function_name = "calendar-backend"
project_name = local.project_name
function_ssm_parameters = [
"google-api-oauth-token",
"google-api-credentials"
]
}
As an example of module output usage, here is the configuration of aws_lambda_permissions resource that I use outside the AWS Lambda module to allow the HTTP API service to invoke the function used as Authorizer:
resource "aws_lambda_permission" "allow_api_gw_invoke_authorizer" {
statement_id = "allowInvokeFromAPIGatewayAuthorizer"
action = "lambda:InvokeFunction"
function_name = module.lambda_api_gw_authorizer.lambda.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.this.execution_arn}/authorizers/${aws_apigatewayv2_authorizer.header_based_authorizer.id}"
}
As a side note, check out this AWS Lambda Operator Guide, which offers specialized advice on developing, securing, and monitoring applications based on AWS Lambda.
Let’s switch to the HTTP API part to see how it looks and learn how it integrates Lambda functions.
I write about AWS, Terraform, and the engineering practices behind reliable infrastructure.
Deep Dive into HTTP API Gateway
Now, we focus on the HTTP API Gateway, delving into its essential concepts, seamless integration with AWS Lambda, and using Terraform efficiently for streamlined configuration.
But before we do that, and since we have partially covered the Terraform code already, I’d like to illustrate the logical connection between three main components of the project’s Terraform codebase: AWS Lambda, HTTP API, and API Routes.
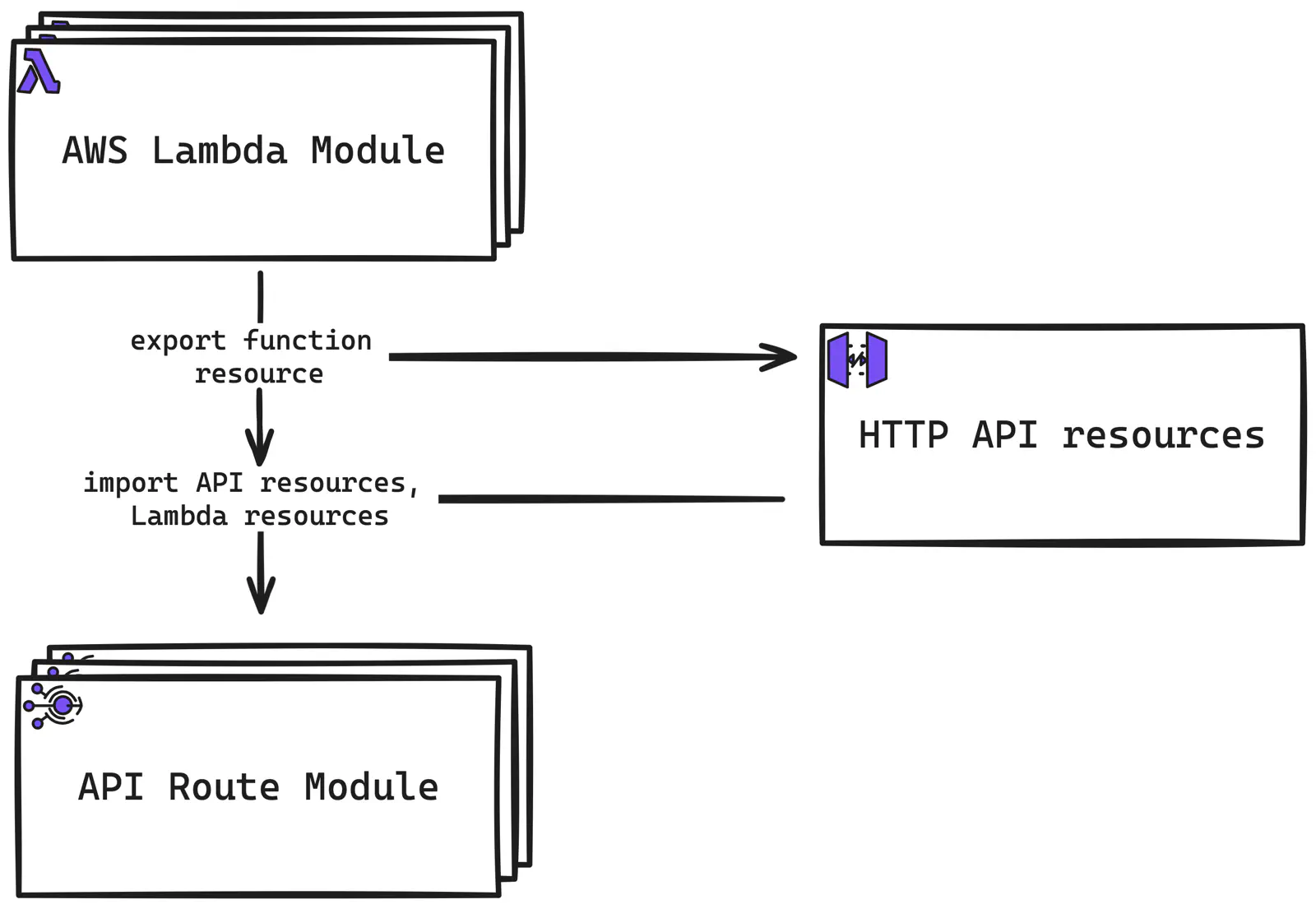
AWS Lambda and HTTP API Terraform integration diagram
I will explain the API Route module in detail a bit later, but for now, for the broader context, here is what happens inside Terraform: AWS HTTP API code logically represents the “global” (within a project) set of resources and uses the function created by the Lambda Terraform module for the Authorizer configuration. Meanwhile, the API Route Terraform module configures specific routes for the HTTP API (hence, requires some info from it) with integration to back-ends implemented by Lambdas (hence, requires some info from them, too).
Back to HTTP API overview. The following components of the HTTP API constitute its backbone:
- Route — a combination of the HTTP method (e.g., GET or POST) with the API route (e.g., /meters). For example: “POST /meters”. Routes can optionally use Authorizers — a mechanism to control access to the HTTP API.
- Integration — the technical and logical connection between the Route and one of the supported back-end resources. For example, with AWS Lambda integration, API Gateway sends the entire request as input to a back-end Lambda function and then transforms the Lambda function output to a front-end HTTP response.
- Stage and Deployment — A stage serves as a designated reference to a deployment, essentially capturing a snapshot of the API at a certain point. It’s employed to control and optimize a specific deployment version. For instance, stage configurations can be adjusted to tailor request throttling, set up logging, or establish stage variables to be used by API (if needed).
Implementing AWS API Gateway V2 HTTP API with Terraform
Below, I detail the Terraform resources essential for implementing the HTTP API, ensuring a transparent and effective setup:
aws_apigatewayv2_api— the HTTP API itself;aws_apigatewayv2_route— the Route for the API that must specify the integration target (e.g., Lambda) and, optionally, the Authorizer;aws_apigatewayv2_authorizer— the Authorizer to use for Routes;aws_apigatewayv2_integration— the resource that specifies the back-end where the API sends the requests (e.g., AWS Lambda);aws_lambda_permission— the resource-based policy for AWS Lambda to allow the invocations from the API;aws_apigatewayv2_stage— the name of the Stage that references the Deployment.
Applying Terraform for HTTP API Gateway and Lambda Authorizer
The HTTP API is the simplest in the API Gateway family (so far), so its Terraform resource has relatively few configuration options, most of which can be left at their default values.
As for the Authorizer, it can have two options for letting API know its decision: simple response and IAM policy.
The simple response just returns a Boolean value to indicate whether the API should allow the request (True) or forbid it (False).
The IAM policy option is customizable and allows crafting custom policy statements that allow granular access to explicitly provided resources.
In this project, I follow the way of simplicity and use the “simple response”, so the response from Lambda Authorizer to HTTP API looks as follows:
{
"isAuthorized": true/false
}
Let’s review the HTTP API resource along with the API Authorizer that I used for all routes:
resource "aws_apigatewayv2_api" "this" {
name = local.project_name
protocol_type = "HTTP"
}
resource "aws_apigatewayv2_authorizer" "header_based_authorizer" {
api_id = aws_apigatewayv2_api.this.id
authorizer_type = "REQUEST"
name = "header-based-authorizer"
authorizer_payload_format_version = "2.0"
authorizer_uri = module.lambda_api_gw_authorizer.lambda.invoke_arn
enable_simple_responses = true
identity_sources = ["$request.header.authorization"]
authorizer_result_ttl_in_seconds = 3600
}
resource "aws_lambda_permission" "allow_api_gw_invoke_authorizer" {
statement_id = "allowInvokeFromAPIGatewayAuthorizer"
action = "lambda:InvokeFunction"
function_name = module.lambda_api_gw_authorizer.lambda.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.this.execution_arn}/authorizers/${aws_apigatewayv2_authorizer.header_based_authorizer.id}"
}
The complete code is available in the project repository.
Consider the following key points when Terraforming this part.
identity_sources argument of the aws_apigatewayv2_authorizer resource: This is where I defined what exactly the Authorizer should validate. I used the header named authorization so the Authorizer Lambda function would check its value to decide whether to authorize the request.
💡 Check out other options available to use as the identity source — Identity sources.
authorizer_uri argument of the aws_apigatewayv2_authorizer resource: It is the invocation ARN of the Lambda function used as Authorizer (not the Lambda’s resource ARN).
authorizer_result_ttl_in_seconds argument of the aws_apigatewayv2_authorizer resource: This allows to skip the Authorizer invocation for the given time if a client provided the same identity source values (e.g., authorization header).
source_arn argument of aws_lambda_permission: Similar to the authorizer_uri argument, this one expects the execution ARN of the HTTP API followed by the Authorizer identifier.
Now, let’s see how Routes are codified with Terraform.
Applying Terraform for HTTP API Routes
💡 Because an API typically has multiple routes, creating another Terraform module that implements the configurable HTTP API Gateway route is beneficial. Hence, the aws_apigatewayv2_route, aws_apigatewayv2_integration, and aws_lambda_permission resources would constitute such a module.
This Terraform module implements a specific use case for HTTP API Gateway. However, if you’re seeking for a generic all-in-one module for API Gateway, I recommend checking out this one — Terraform AWS API Gateway Module by Anton Babenko.
resource "aws_apigatewayv2_route" "this" {
api_id = var.api_id
route_key = var.route_key
authorization_type = "CUSTOM"
authorizer_id = var.authorizer_id
target = "integrations/${aws_apigatewayv2_integration.this.id}"
}
resource "aws_apigatewayv2_integration" "this" {
api_id = var.api_id
integration_type = "AWS_PROXY"
connection_type = "INTERNET"
integration_uri = var.lambda_invocation_arn
payload_format_version = "2.0"
}
resource "aws_lambda_permission" "this" {
statement_id = "allowInvokeFromAPIGatewayRoute"
action = "lambda:InvokeFunction"
function_name = var.lambda_function_name
principal = "apigateway.amazonaws.com"
source_arn = "${var.api_gw_execution_arn}/*/*/*/*"
}
First, I want to highlight several key aspects for understanding the resources’ arguments within that module.
The target argument of the aws_apigatewayv2_route resource implies that the integration ID should be prefixed with the “integrations/” keyword.
While the connection_type argument of the aws_apigatewayv2_integration resource specifies “INTERNET”, it does not mean that the Lambda function must have the publicly available URL. This value must be used unless you work with a VPC endpoint for API Gateway for internal usage.
For the source_arn argument in the aws_lambda_permission resource, similar to earlier, it requires the execution ARN of the API. However, this time, it is the integration of the HTTP API Route with Lambda. And the ARN format of this one is different and a bit tricky:
arn:partition:execute-api:region:account-id:api-id/stage/http-method/resource-path
The arn:partition:execute-api:region:account-id:api-id part constitutes the execution ARN of the HTTP API itself, so for the sake of simplicity, I decided to go with wildcards after it.
For your convenience, here is the detailed specification of API Gateway ARNs.
The HTTP API Route module expects several input variables:
authorizer_id— the identifier of the Authorizer to use on this route;route_key— the route key for the route, e.g.,GET /foo/bar;api_id— the identifier of HTTP API created earlier;lambda_invocation_arn— the Invocation ARN of the Lambda function;lambda_function_name— the name of the Lambda function to integrate with the route;api_gw_execution_arn— the Execution ARN of the HTTP API that invokes a Lambda function.
Let’s take a closer look on API Gateway V2 HTTP API route.
A route consists of an HTTP method and a resource path with an optional variable. Based on the pre-defined convention, it uses a simplified routing configuration and methods request model (comparable to other APIs).
While I was working with the HTTP API, I found this simplified approach to be great because it allows easy access to the request context from AWS Lambda functions, for example:
- A path variable in a route, e.g.,
GET /calendars/{calendar-name}, would be available for the integrated AWS Lambda by its name inside the pathParameter JSON field, e.g.,pathParamters.calendar-name, of the event object sent by API to Lambda. In other words, you do not need to explicitly set the mapping between the path variable and its representation to the back-end. - A request query string is parsed into separate parameter-value pairs and available in the
queryStringParametersfield of the event object sent by API to Lambda. Again, without the explicit mapping configuration.
Here, you can read more about the Route specification of HTTP API and how to transform requests and responses from the API side if you need to adjust something:
Now back to Terraform. Below is the code snippet that illustrates the call of the API Route Terraform module:
module "route_calendars" {
source = "./modules/api-gateway-route"
api_id = aws_apigatewayv2_api.this.id
route_key = "GET /calendars/{calendar-name}"
api_gw_execution_arn = aws_apigatewayv2_api.this.execution_arn
lambda_invocation_arn = module.lambda_calendar_backend.lambda.invoke_arn
lambda_function_name = module.lambda_calendar_backend.lambda.function_name
authorizer_id = aws_apigatewayv2_authorizer.header_based_authorizer.id
}
This module logically relies on both the HTTP API and Lambda resources to configure their integration by implementing the Route.
Enhancing Security and Monitoring of AWS API Gateway V2 HTTP API
Several additional options are available to monitor and protect the HTTP API: logs, metrics, and throttling.
Overview of HTTP API monitoring and protection options
Logging, metrics, and throttling are configured on the Stage level but allow configuration granularity for the Routes.
For logs, you can configure the CloudWatch log group, the log format (JSON, CLF, XML, CSV), and content filters. The logging variables allow you to customize the information that appears in logs. I will provide an example of such a configuration later in the article.
By default, API Gateway sends only API and stage-level metrics to CloudWatch in one-minute periods. However, you can enable detailed metrics and additionally collect the per-route metrics.
To safeguard your HTTP API from excessive requests, you can employ throttling settings, which allow you to set limits per individual route as well as for all routes collectively.
Configuring monitoring and protection for HTTP API with Terraform
Now, let’s see how Terraform helps configure the protection and monitoring for HTTP API.
As mentioned earlier, API Gateway applies these configurations at the Stage level, which is why the aws_apigatewayv2_stage resource encapsulates them all.
resource "aws_apigatewayv2_stage" "default" {
api_id = aws_apigatewayv2_api.this.id
name = "$default"
auto_deploy = true
description = "Default stage (i.e., Production mode)"
default_route_settings {
throttling_burst_limit = 1
throttling_rate_limit = 1
}
access_log_settings {
destination_arn = aws_cloudwatch_log_group.api_gateway_logs_inkyframe.arn
format = jsonencode({
authorizerError = "$context.authorizer.error",
identitySourceIP = "$context.identity.sourceIp",
integrationError = "$context.integration.error",
integrationErrorMessage = "$context.integration.errorMessage"
integrationLatency = "$context.integration.latency",
integrationRequestId = "$context.integration.requestId",
integrationStatus = "$context.integration.integrationStatus",
integrationStatusCode = "$context.integration.status",
requestErrorMessage = "$context.error.message",
requestErrorMessageString = "$context.error.messageString",
requestId = "$context.requestId",
routeKey = "$context.routeKey",
})
}
}
Here, I applied the default throttling settings: for my project, 1 request per second was enough at that point.
🤔 There is a nuance, though, that makes Terraforming API Gateway a little inconvenient — the IAM role that allows API to write logs must be defined on a region level. Therefore, if you maintain several Terraform projects for the same AWS account, you might need to have the following configuration stand separately to avoid conflicts or misunderstandings:
resource "aws_api_gateway_account" "this" {
cloudwatch_role_arn = aws_iam_role.api_gateway_cloudwatch_logs.arn
}
resource "aws_iam_role" "api_gateway_cloudwatch_logs" {
name = "api-gateway-cloudwatch-logs"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal = {
Service = "apigateway.amazonaws.com"
}
Action = "sts:AssumeRole"
}
]
})
}
resource "aws_iam_role_policy_attachment" "api_gateway_cloudwatch_logs" {
role = aws_iam_role.api_gateway_cloudwatch_logs.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs"
}
resource "aws_cloudwatch_log_group" "api_gateway_logs_inkyframe" {
name = "/aws/apigateway/inkyframe"
log_group_class = "STANDARD"
retention_in_days = 7
}
And one more thing about HTTP API deployments and stages. I use the special $default keyword to have a single stage (hence, the default one), and I also used automatic deployments: with any change made to API configuration, AWS will automatically generate a new Deployment and bound it with the Stage. If you prefer controlling deployments manually, there is a special resource exists that implements this — aws_apigatewayv2_deployment
resource "aws_apigatewayv2_deployment" "example" {
api_id = aws_apigatewayv2_api.example.id
description = "Example deployment"
triggers = {
redeployment = sha1(join(",", tolist([
jsonencode(aws_apigatewayv2_integration.example),
jsonencode(aws_apigatewayv2_route.example),
])))
}
lifecycle {
create_before_destroy = true
}
}
In that case, the aws_apigatewayv2_stage resource requires the deployment_id argument to link itself with a particular Deployment and, therefore, represent the state of the API configuration.
Also, API Gateway requires at least one configured API Route before the deployment is initiated/created. However, these resources do not explicitly depend on each other via attribute references. To avoid the race condition in Terraform, you need to reference the Route resource in the aws_apigatewayv2_deployment resource via the triggers argument (as shown above) or via the depends_on meta-argument. Otherwise, Terraform will try to apply changes to both resources simultaneously.
Afterword: Simplifying Serverless Architectures
In wrapping up our exploration of AWS HTTP API Gateway, AWS Lambda, and Terraform, we’ve delved into how these powerful tools work in tandem to streamline and enhance serverless architectures. This article aimed to combine my experience with new knowledge and demystify the complexities of used services, showcasing their capabilities in creating efficient, cost-effective solutions for modern cloud-based applications.
We focused on practical implementation and the tangible benefits of combining these technologies. By leveraging Terraform, we’ve seen how infrastructure management can be simplified, allowing for clearer, more maintainable code. The combination of AWS Lambda and HTTP API Gateway has demonstrated the efficiency of serverless computing, offering scalability and performance without the burden of extensive configuration and management.
This exploration underlines the importance of choosing the right tools and strategies in cloud computing. It reminds developers and architects that creating robust and efficient serverless systems is within reach with a thoughtful approach and the right set of tools. As the cloud landscape continues to evolve, staying informed and adaptable is key to harnessing the full potential of these technologies. 💚