
Many of us know and use Packer to build golden images for cloud providers. But did you know that Packer is not just a CLI tool?
There is an HCP (stands for HashiCorp Cloud Platform) Packer that acts as the image registry that stores the image metadata, allows you to organize images in distribution channels, and perform other management actions.
In this blog, I would like to showcase some features of the HCP Packer and explain how you can use it to set up an image factory for the organization (or for your own fun 🙃) to maintain the Golden Images.
I will be using AWS AMI as the OS image appliance for examples in this blog, but Packer supports many other formats and clouds through its plugins.
HCP Packer Registry
HCP Packer is the image metadata registry that stores the information (not an image file) about OS images you create using the Packer CLI tool.
It solves the challenge of the Golden Image pipeline maintenance by acting as a hub that organizes and streamlines the processes of OS image creation, usage, and continuity.
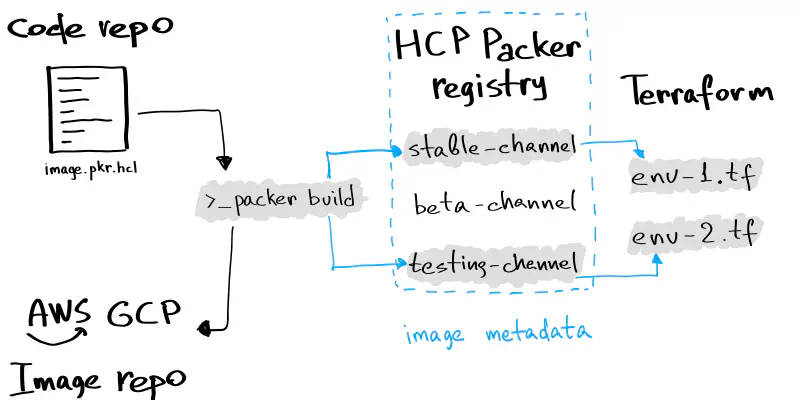
OS Image lifecycle with HCP Packer
HCP Packer introduces several new concepts that compose the registry: Image Buckets, Iterations, and Channels. Further in this blog, I will explain them, but let’s start with security first.
Security First — Creating Service Principals
Before launching the builds, you need to create a Service Principal to allow your local Packer CLI to communicate with the HCP.
I recommend creating at least two principals: the one with the “contributor” role — used by Packer CLI to store the image metadata in HCP; and another one with the “viewer” role — used by Terraform (as it requires only read-level access for Packer HCP).
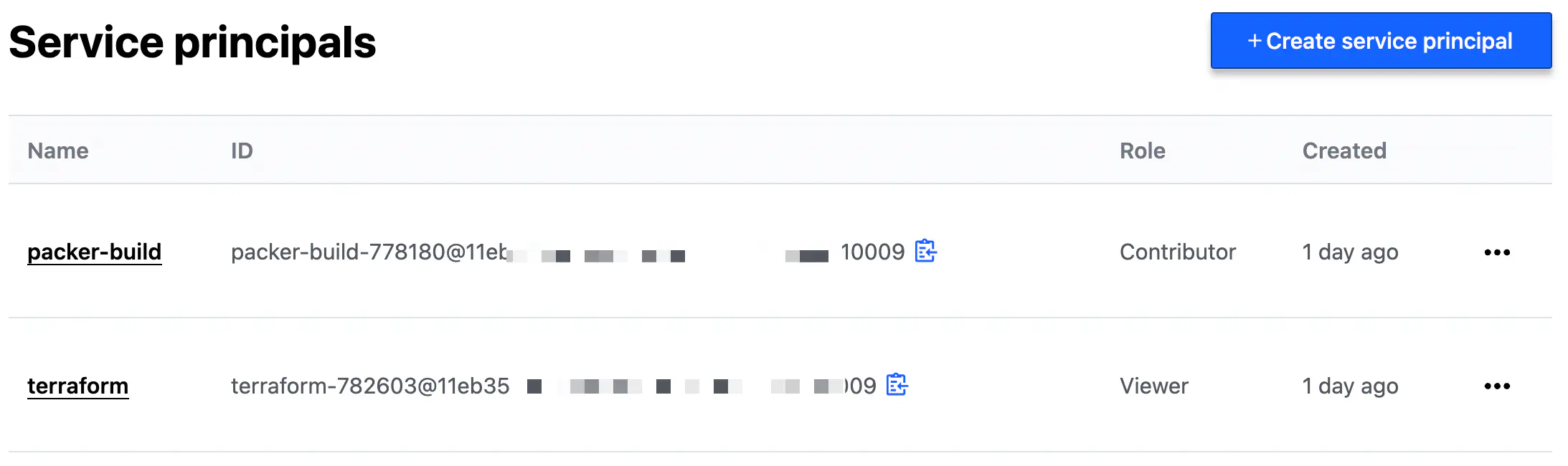
Service Principals for HCP
Once you have created a principal, you can generate a key for authentication. The key consists of an ID and a secret.
Both the Packer CLI and the Packer Terraform provider support environment variables for the principal client ID and client secret for authentication:
HCP_CLIENT_ID and HCP_CLIENT_SECRET
Image Buckets to Store Image Metadata
The central entity in HCP Packer is the Image Buckets.
Image Bucket is a repository where the metadata from a Packer template is stored once image(s) creation is completed.
Image Bucket can contain a single image or several images if you define several sources for the build block in the Packet template.
For example, a bucket can span several custom AMIs based on Ubuntu AMI provided by Amazon and built and distributed within several regions.
You cannot create buckets manually from the web interface (at least as of June 2022), but I will show you how they are defined as code inside a Packer template file just a bit later.
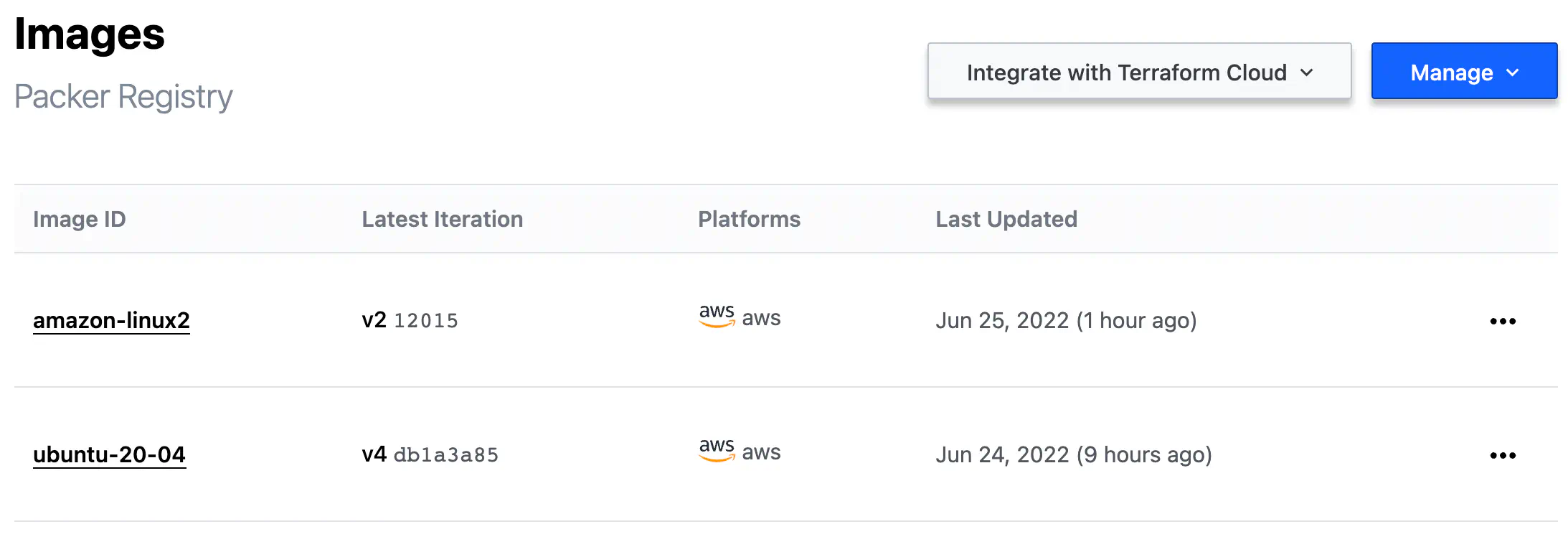
HCP Packer Image Buckets
Iterations of Image Creation
Every execution of the build action made by Packer CLI (if used in conjunction with HCP) is recorded specially and called Iteration.
Each Iteration has a unique fingerprint — an SHA value of the head reference in the Git repository that contains your Packer template.
HCP_PACKER_BUILD_FINGERPRINT env variable if you want to set the Iteration ID manually.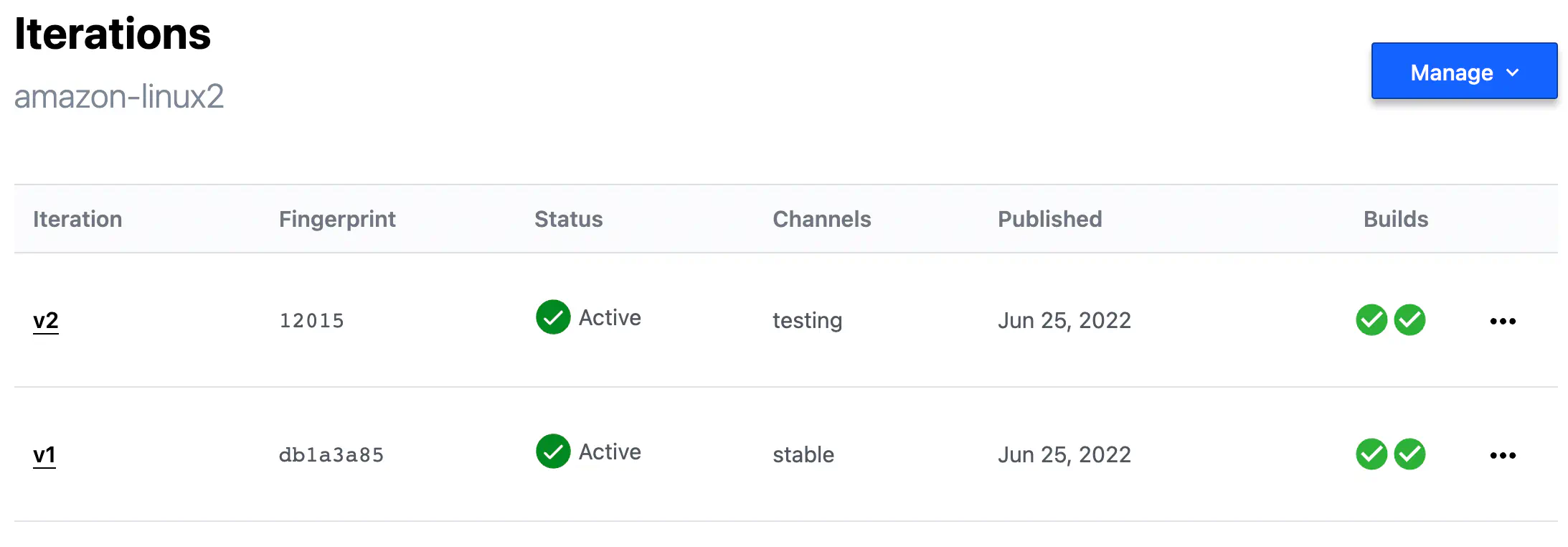
HCP Packer Iterations
Every Iteration consists of at least one Build — another special record that contains image metadata produced by Packer CLI.
The Builds inside Iteration are represented by the number of sources specified in your Packer template’s build section.
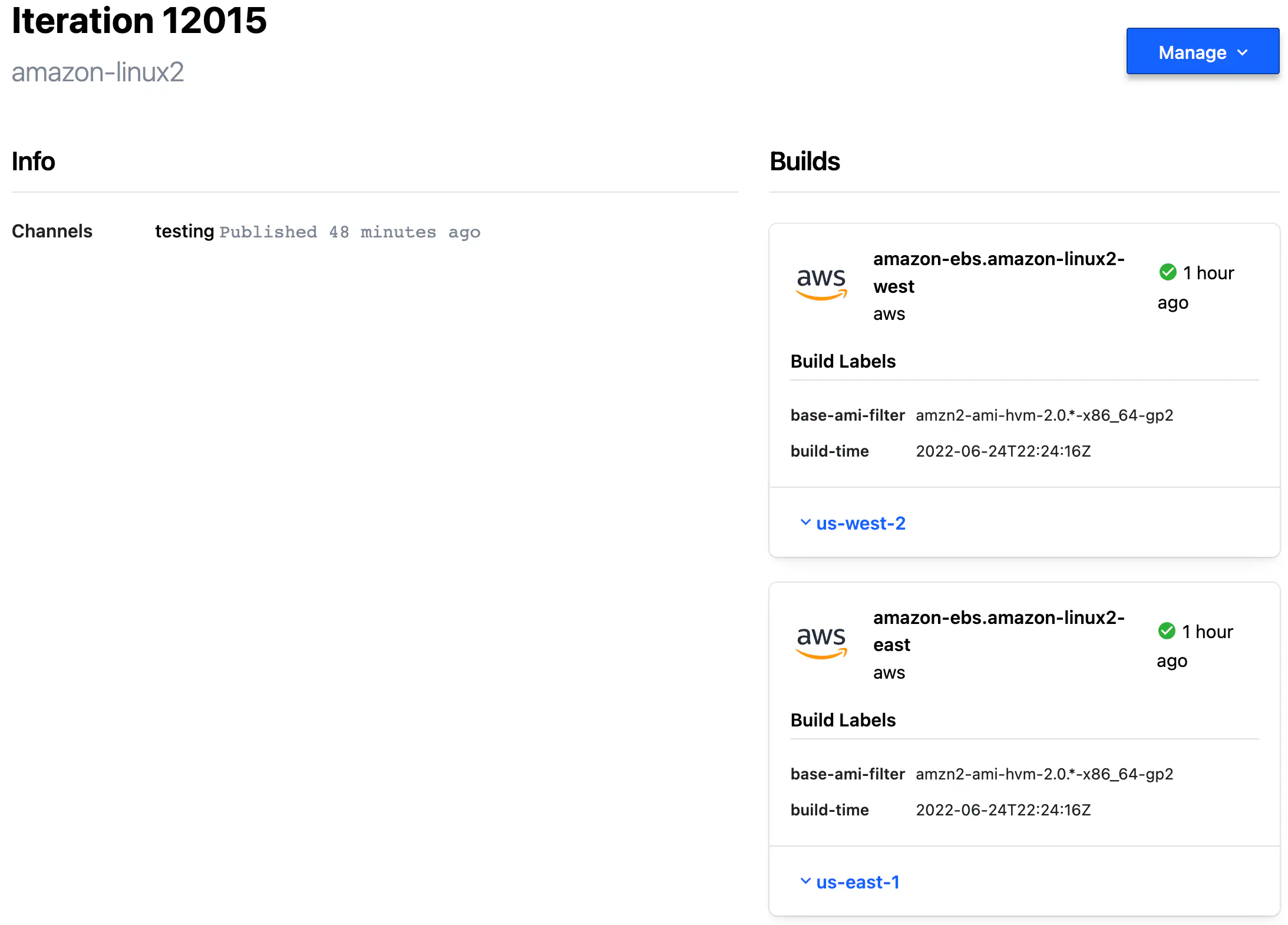
HCP Packer Iteration Builds
Packer Template Configuration for HCP
Let’s now review a code example to understand how all this combines.
Here is a build block from Packer template file.
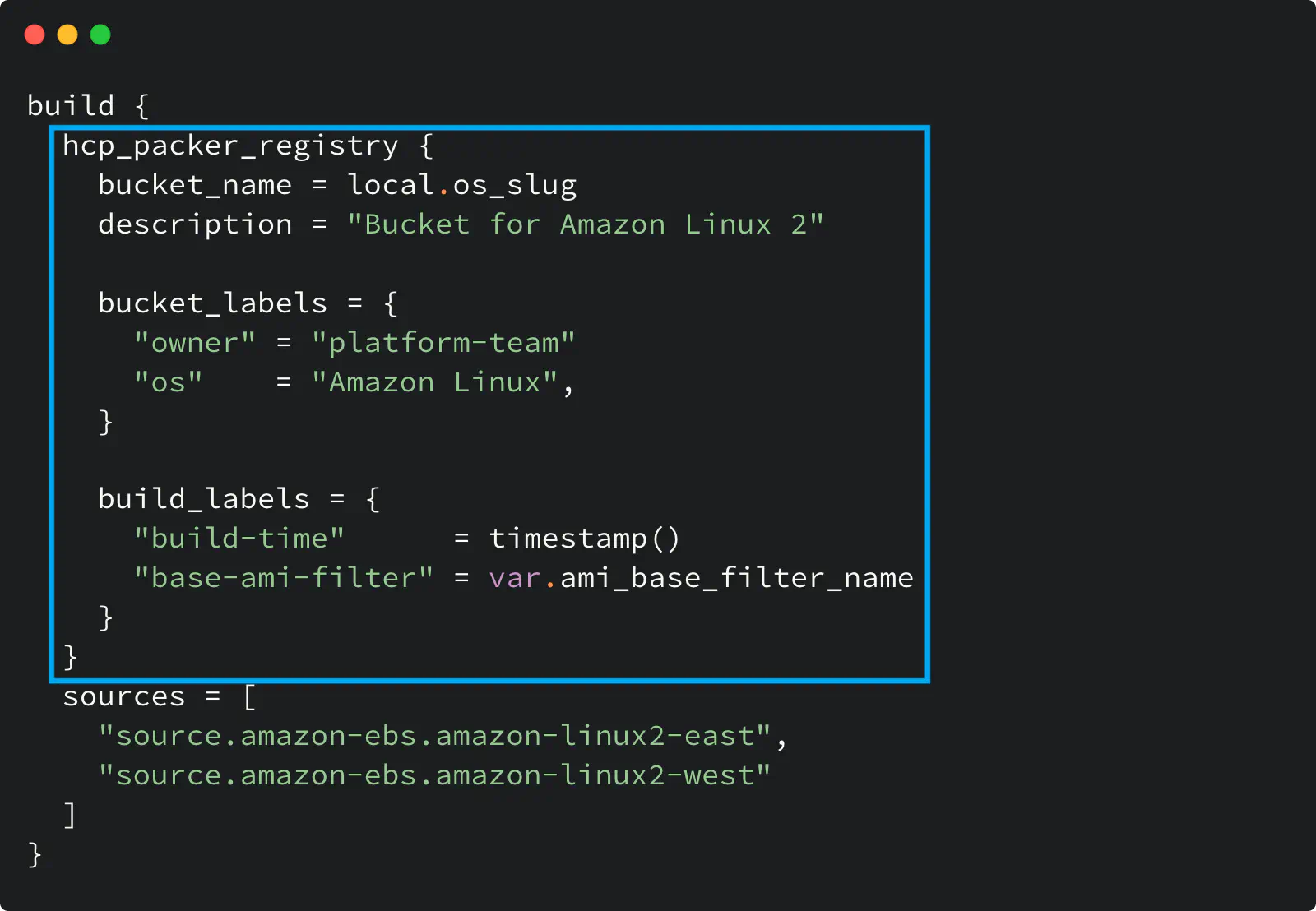
HCP Packer registry usage in a Packer template
Look at the hcp_packer_registry block: it defines the Bucket where Packer will store image information and custom labels for the Bucket and the image.
The bucket_name defines my Image Bucket: Packer will either use the existing Bucket with that name or create a new one if it does not exist.
The bucket_labels map defines custom labels you specify for an Image Bucket. In my example, I set the Bucket owner and the OS name.
The build_labels map defines custom labels for the Builds within the Iteration inside a bucket.
And because I define two sources here, my Iteration will have two Builds inside it.
Using Channels
Although all Iterations have unique identifiers, giving a familiar name to some of them would be more convenient.
Channel is a way to assign a specific Iteration to a friendly name that you can use later:
- in other Packer templates, if you want to use your custom image as the base for other images
- in Terraform code (we will review this further) to reference the image by the channel name, avoiding the hard code of the image ID.
Channels are created through the web interface or using the API. And I hope HashiCorp will add HCP Packer resources to the HCP Terraform provider in the future so channel creation can be described as code.
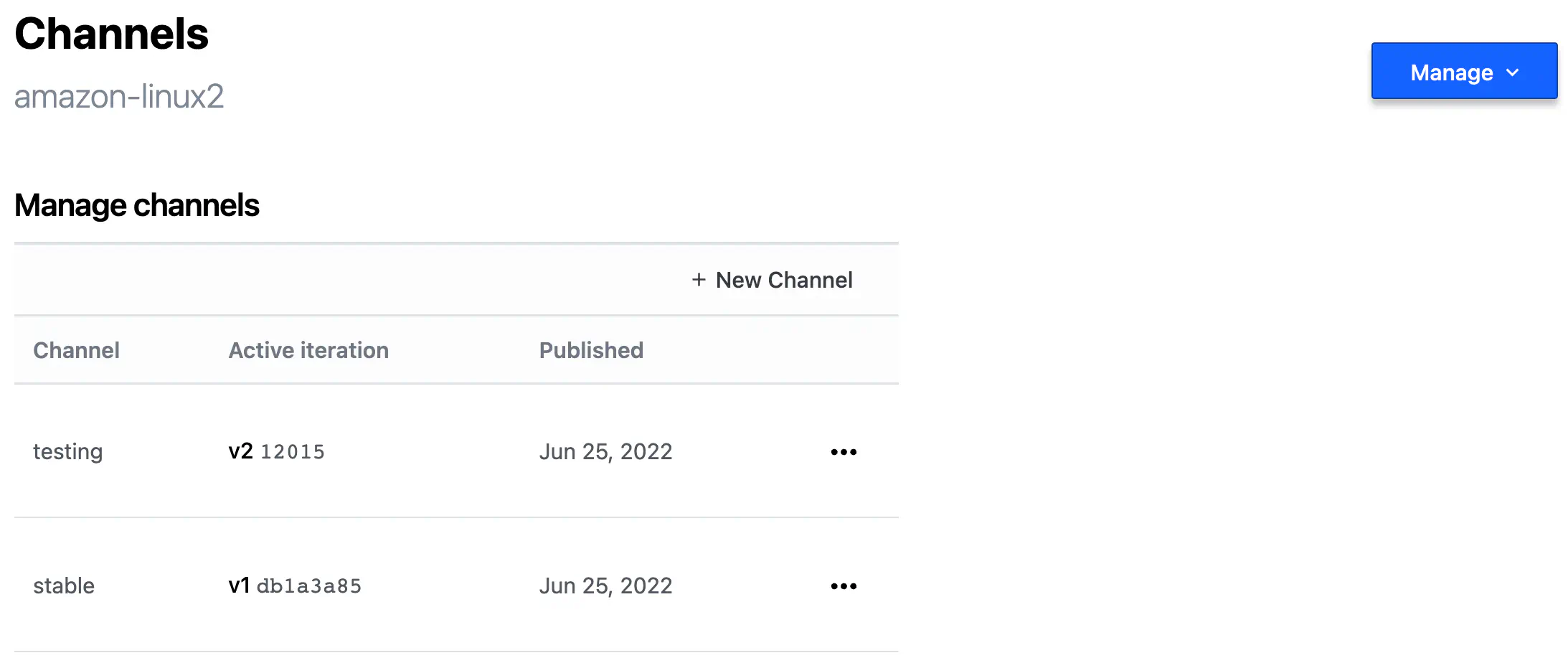
HCP Packer Image Channel
You can manually promote an Iteration to a channel with a web interface.
But before promoting an Iteration to a channel, you might want to perform the following:
test and validate the newly created image before its promotion to a channel: create a temporary virtual machine using Terraform and ensure it successfully boots from the image.
assess that VM with some vulnerability scanning service. For example, if you’re an AWS customer, then Amazon Inspector might work for you in such a case.
Once an image from the Iteration is validated and passed the security assessment, it’s safe to promote that Iteration to a channel.
HCP Packer provides a rich API that you can leverage to automate that process.
When a packer build successfully finishes its execution, it returns the Iteration ID (ULID) that you can use later for an API call with a request to promote the new Iteration to a channel.
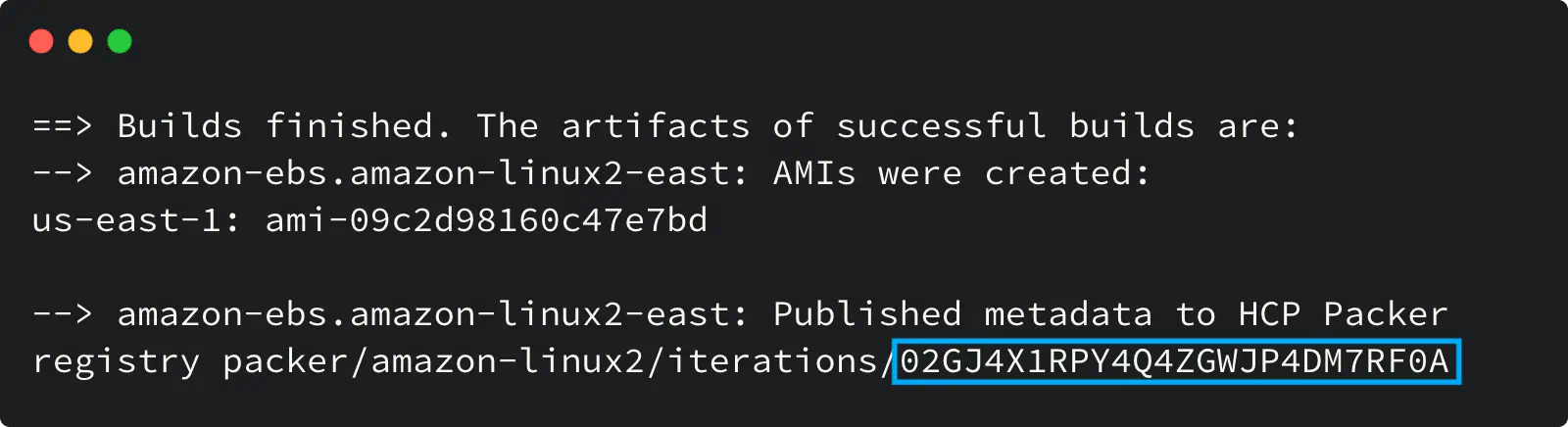
Packer build output with Iteration ULID
The “Update Channel” PATCH API method is needed to assign the Iteration to a channel.
First, you need to obtain the access token as described in this guide.
Then, the following cURL request can be used to update the channel with a new Iteration ULID (please expand the code snippet below):
Click here to see the code snippet
HCP_ACCESS_TOKEN="your token here"
HCP_ORG_ID="your org id here"
HCP_PROJECT_ID="your project id here"
HCP_BUCKET_NAME="amazon-linux2"
HCP_CHANNEL_NAME="stable"
HCP_BASE_URL="https://api.cloud.hashicorp.com/packer/2021-04-30"
curl -X PATCH \
--header "Authorization: Bearer $HCP_ACCESS_TOKEN" \
--data '{
"incremental_version":"3",
"iteration_id":"01H8V7WBDWRBCMZDZ2HG3MKSDL"
}' \
"${HCP_BASE_URL}/organizations/${HCP_ORG_ID}/projects/${HCP_PROJECT_ID}/images/${HCP_BUCKET_NAME}/channels/${HCP_CHANNEL_NAME}"
Using HCP Packer with Terraform
Having a streamlined golden image creation process is good. Still, it would be even better to have an easy way to always use the latest validated image without hardcoding or some other duck taping.
With the help of the HCP Terraform provider, you can reference the image channel in your Terraform code and have a completed end-to-end workflow.
Here is an example of the Terraform configuration that uses the HCP Packer registry as the source of AMI ID for an AWS instance:
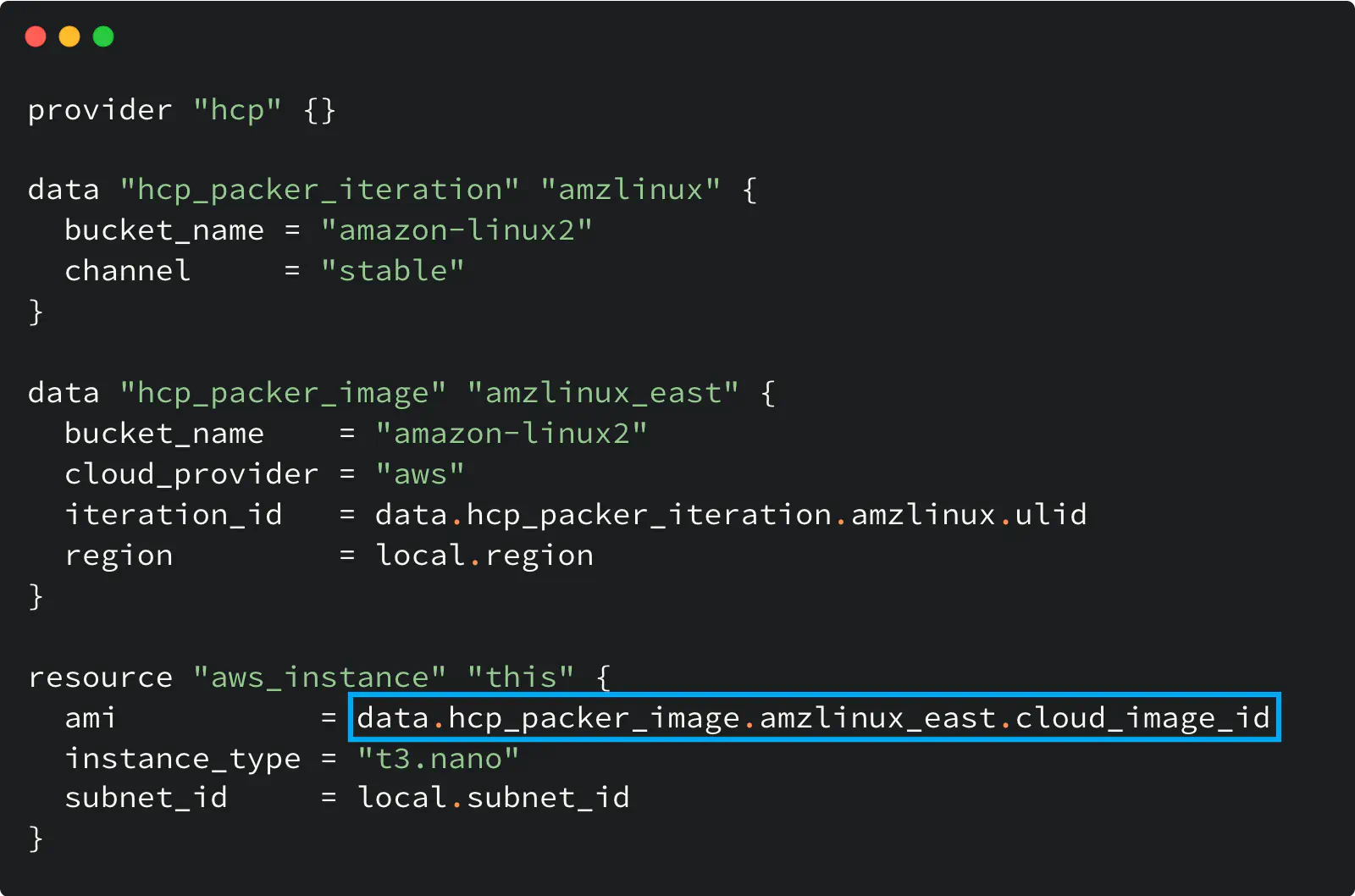
Using HCP Packer registry with Terraform
Two data sources do all the magic here.
The hcp_packer_iteration data source gets the most recent Iteration assigned to the specified Channel (i.e., latest). We need that because the Iteration (not the Channel) holds the image information.
Then the hcp_packer_image gets the cloud image ID (AWS AMI ID in my example) from that Iteration so you can use it later in your code.
The configuration of the hcp provider in this example is empty on purpose: this provider supports HCP_CLIENT_ID and HCP_CLIENT_SECRET env variables to use their values for the authentication and avoid hard coding. Alternatively, you can use the client_id and client_secret options to configure the provider.
Image revocation
It is possible to revoke a specific Iteration, and therefore all Images in it, to alert the users about the Image decommission. For example, your SecOps team can revoke it due to the new CVE announced.
Revoked Images are treated differently by Packer CLI and Terraform CLI.
Packer CLI and Revoked Image
When you reference the Image in a Packer template to use it as a source for another image, its revocation makes further Packer builds to fail.
In other words, Packer won’t let you build a new Image on top of the revoked Image.
Terraform CLI and Revoked Image
On the contrary, Terraform CLI does not prevent the usage of the revoked Image by default, although its Cloud version does it if used with the “Run tasks” feature.
Although you can get the Image ID, when the Iteration is revoked, the hcp_packer_image data source returns a non-empty revoke_at attribute with the value set to the revocation timestamp.
Therefore, you can use the precondition (available in Terraform CLI v1.2.0 and higher) to validate the Image with Terraform CLI and make sure it was not revoked
Here is the code example that illustrates that:
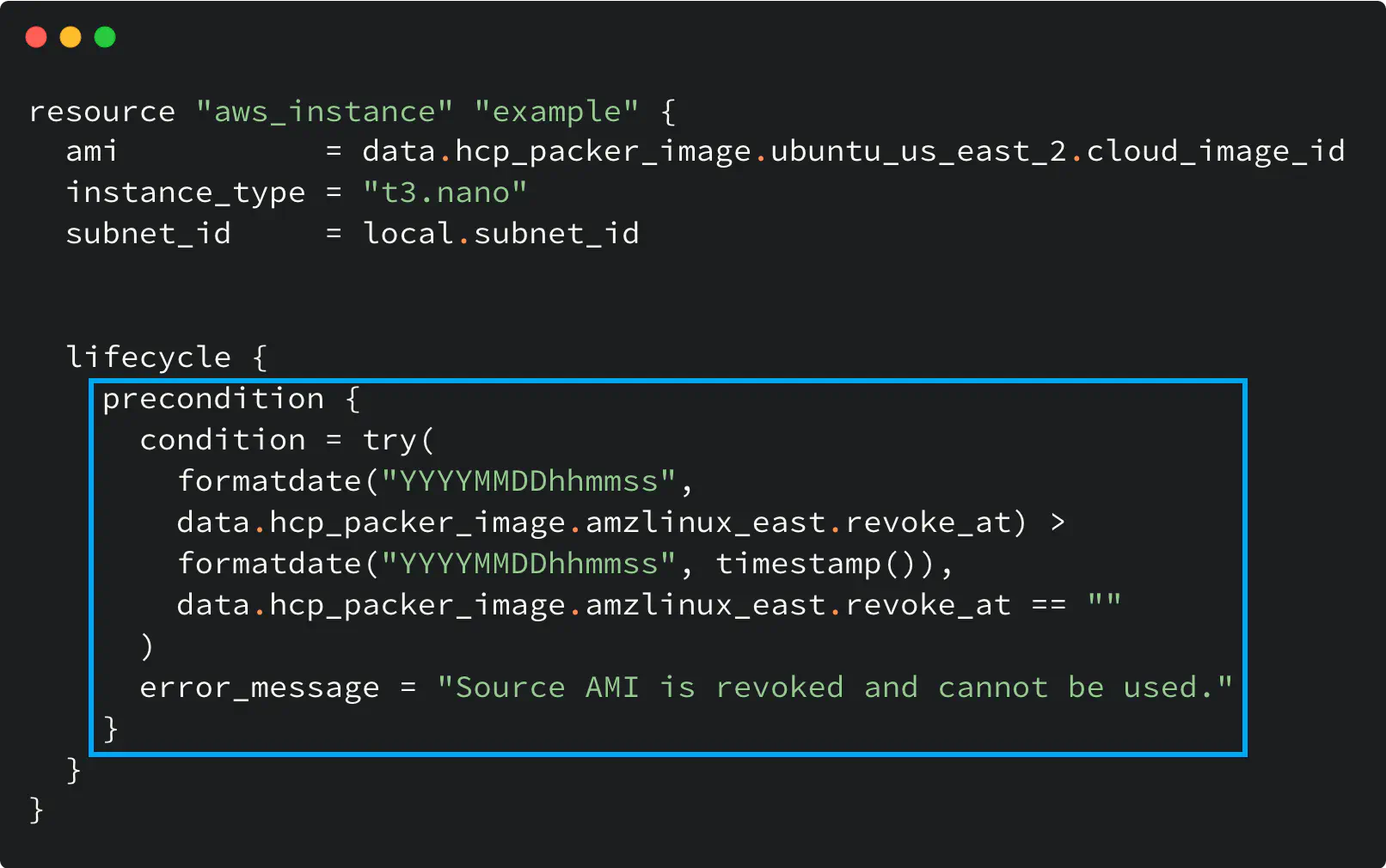
Work with revoked HCP Packer image in Terraform
Why HCP Packer?
So what makes the HCP Packer a good fit and worth a try?
1️⃣ A centralized place to view and manage the OS images throughout an organization. And as for me, it is good to have a neat web panel to look at things.
2️⃣ Image Channels that help with logical organization and control.
3️⃣ Ability to revoke an image to prevent its usage.
4️⃣ API and Terraform provider as additional tools that enrich the user experience.
When dealing with multiple golden images or with various cloud providers, the HCP Packer can be a good fit for your image pipeline.
As a registry, it enables the end-to-end workflow for golden image usage: create, validate, use and decommission the images in a centralized way.
And no more hard-coded IDs, manual variable settings, or other duck tape and glue in your Terraform.
If you want to learn more about HCP Packer and have some practice, I suggest starting from the tutorial at HashiCorp Learn portal.